[This web page comprises my contributions to a special issue of the journal Corpus Linguistics and Linguistic Theory (vol. 3 no. 1, 2007). I was asked to write a “target article”, which appears immediately below; various scholars wrote responses to the target article, and I wrote a reply to the responses, which appears here after the target article. I cannot reproduce the respondents’ contributions here, but it may be that some parts of my reply will be of use independently of that context.]
Grammar Without Grammaticality
Geoffrey Sampson
Department of Informatics, Sussex University
Introduction
A key intellectual advance in 20th-century linguistics lay in the realization that a typical human language allows the construction not just of a very large number of distinct utterances but actually of infinitely many distinct utterances. However, although languages came to be seen as non-finite systems in that respect, they were seen as bounded systems: any particular sequence of words, it was and is supposed, either is well-formed or is not, though infinitely many distinct sequences are each well-formed. I believe that the concept of “ungrammatical” or “ill-formed” word-sequences is a delusion, based on a false conception of the kind of thing a human language is.
In order to give an intuitive sense of the conception which I believe ought to replace it, let me quote the remark sometimes made by hail-fellow-well-met types: “There are no strangers, only friends I haven’t met yet” – that is, rather than the world being divided into two sorts of people with respect to our mutual relationships, namely friends and strangers, inherently all people are of the same friendly sort, though in a finite lifetime one has the chance to establish this only for a subset of them. Whether or not this is a good way of thinking about human beings, I believe it is a good way of thinking about word-sequences.
The point of view I am arguing against was put forward (for the first time, so far as I know) almost fifty years ago, by Noam Chomsky in Syntactic Structures:
The fundamental aim in the linguistic analysis of a language L is to separate the grammatical sequences which are the sentences of L from the ungrammatical sequences which are not sentences of L and to study the structure of the grammatical sequences. (Chomsky 1957: 13)
After this principle was stated in 1957, it quickly became central to much of what happened in theoretical linguistics, and it continues to be so. With respect to the recent period, I am not in a position to make that assertion on the basis of my own experience of the field, because I have been fairly disengaged from linguistics as an academic discipline since moving to a computing department in 1991. I therefore checked my impression that Chomsky’s principle retains its influence, by looking through the few introductory grammar textbooks which are seen by the linguistics department of my university (not by any means regarded by other linguists as a strongly “Chomskyan” or “formal” group, I believe) as basic and up-to-date enough to be placed in the Reserve section of our library. I quickly encountered the following:
To really get at what we know about our languages (remember syntax is a cognitive science), we have to know what sentences are not well-formed. That is, in order to know the range of what are acceptable sentences of English, Italian, or Igbo, we first have to know what are not acceptable sentences in English, Italian, or Igbo. This kind of negative information is not available in corpora … (Carnie 2002: 10–11)
This particular remark goes further than Chomsky, by making the status of ill-formed sequences even more fundamental than that of well-formed sequences to the definition of a language (“first have to know”, Carnie’s italics). Although other items in the Reserve collection of textbooks did not express Chomsky’s principle so explicitly, many of them contained passages in which it seemed more or less implicit (and certainly I found nothing in any of them contradicting it). Contrary to Carnie, I do not believe that getting at what we know about the things we can say in our language requires us to study a range of things we cannot say (let alone to give that study priority). I do not believe that there is in an interesting, relevant sense a “range of things we cannot say”.
Unfamiliar does not imply ungrammatical
Consider one particular example of a word-sequence of questionable status – I quote this particular case just because it happened to catch my eye in a book I was reading when I embarked on writing this paper, namely John Mortimer’s novel Dunster, but I believe it would be easy to find any number of comparable examples:
… Dunster seemed to achieve, in the centre of this frenzied universe, an absence of anxiety which I had never known. But then, as I have made it clear to you, I worry. (Mortimer [1993] 1994: 21)
When I read this it seemed to me that, if I had written it, I would have omitted the it in made it clear. Yet John Mortimer’s spoken and written output has as good a claim as anyone’s to be a model for the kind of English I think of myself as aiming to speak and write. Mortimer is highly educated (Harrow and Brasenose) and has lived by the spoken and written word, combining a career at the Bar with a prolific and successful output of intelligent fiction, notably the Rumpole series, and frequent broadcasting on current affairs. His style is direct and unpretentious. And Penguin books normally seem to be carefully copy-edited. On the face of it one would expect that if Mortimer and Penguin between them let a sentence into print, I ought to be happy with it from a grammatical point of view. Of course we are told that even individuals from the same regional and social dialect background may have odd differences between their personal idiolects (and random slips of the pen and misprints can always occur). So I tried to work out what the basis was for my adverse reaction to this passage, which I certainly understand perfectly well.
Subordinate clauses introduced by as are of (at least) two kinds: sometimes as means roughly the same as because, and in that case this clause would be grammatically normal (but would not make sense in the context); the other kind of as clause, which is the one we are evidently dealing with here, introduces an appositive relative clause which modifies not a noun phrase but the proposition expressed by the higher clause to which it is attached. A straightforward example would be As you know, I have to leave by four – meaning “I have to leave by four, and you know that I have to leave by four”. In relative clauses it is usual, at least in “good” English, to omit the relativized element (unless it is represented by a wh- pronoun at the beginning of the clause) – thus, know is a transitive verb, but the clause As you know does not itself contain an object. This is undoubtedly the reason why I was surprised when I read as I have made it clear to you. But on the other hand, this is a more complicated clause; recast in main-clause form it could very easily contain an extraposition structure – I have made it clear to you that I worry. So, whether one would expect to find it in the as clause depends on whether the relativized object to be deleted is counted as covering both parts of the extraposition structure, it … that I worry, or only the “substantive” part, that I worry. But it seems to me that there is no obvious way in which one can infer the expected answer to that question from more common sorts of relative clause, since they will not contain extraposition of the relativized element. One can say I worry, which I have made clear to you – but in that case the propositional object of made is represented by a relative pronoun and no possibility of extraposition arises. So, although I would not myself have written as Mortimer did, I have no grounds for regarding Mortimer’s usage as contrary to the norms of usage I recognize.
The issue is further complicated by the fact that there are socially-deprecated varieties of English in which relativized items are not omitted – one hears phrases like that girl which you know her. While I am sure that neither Mortimer nor I would dream of using that language variety in our writing, it seems normal enough that a grammatical feature which has special social implications in one environment might entirely lack those implications in a different environment; for instance, it is socially frowned on to reduce a possessive pronoun + house phrase to a bare possessive pronoun in a non-contrastive situation but perfectly acceptable in a situation of contrast: someone who says she’ll be coming round to ours rather than … to us or … to our house/place/… categorizes himself socially, whereas someone who says she looked at several houses and decided to buy ours does not. The social connotations of non-deletion of relativized items could similarly fail to apply in the case of extraposition structures.
The upshot of this rather lengthy consideration of a commonplace example is that it seems inappropriate to explain my response to John Mortimer’s usage by saying that he and I have slightly different idiolects. What the preceding analysis suggests to me is that Mortimer’s usage is in fact quite all right in English as I speak and write it – only I had not realized that before. It is rather as if I had got into the habit of walking to work one way but there was another equally suitable way that I happened not to take; perhaps, now my attention has been drawn to it, I shall sometimes in future go that way. It may be that some would argue that that is all that is meant by “different idiolects”, but it seems to me that the term is normally used with an implication of something more like a block on the paths not taken: if Mortimer and I word as-relatives differently, that is because we are walking through towns with similar but non-identical streetplans, and the lane he has gone down is not there in my town. The truth, surely, is that we are walking through the same town, and I had never before noticed the possibility of going his way.
If this sounds too metaphorical to mean very much, consider a non-grammatical example. If someone asks me to name the days of the week, I list them beginning with Monday. Many people (I have no idea what the relative proportions are) begin with Sunday. Would one say that we have different idiolects? Surely it would be unreasonable to say that we are speakers of even slightly different languages, because of a difference of habits like this. We understand each other perfectly well; we might perfectly readily adopt the other sequence, and probably would if there were ever some practical reason to do so; we just happen to have fallen into the Sunday-first or the Monday-first habit and never had a reason to change. This does not seem at all like the fact that some people are English-speakers and others are Italian-speakers. It is more like the fact that some English-speakers take tea at breakfast and others prefer coffee.
If that is fair comment about the alternative ways of listing days, my suggestion is that what are commonly regarded as idiolect differences are often much more akin to the Sunday-first v. Monday-first contrast than to actual differences of language. Furthermore, it is not just that each of us individually has got into the habit of using only a proper subset of a fixed set of grammatical structures which the language as a whole makes available to us, so that we may individually expand the range of things we say without the language expanding: using a language means putting words together in more or less novel ways, so that as a language community uses its language it will very frequently happen that uses are found for sequences of words which had no use previously. Calling such phenomena changes in the language, comparable to the changes studied by historical linguists such as the Great Vowel Shift, seems as misguided as treating Sunday-first v. Monday-first as an idiolect difference. The community is simply progressively discovering more and more ways to achieve rhetorical goals by putting words together, and although this is a process that unrolls through time so that not all possibilities are well-established at any given date, there is no reason to think that any particular sequences of words are definitely “out of bounds” at a given date – perhaps in fact it will not happen to be for several decades before someone first finds a use for sequence X, but it could be today.
My example of two ways of forming as-relatives illustrated the questionable nature of the “idiolect” concept but did not illustrate the idea that language-users find new things to do with their language. As a very simple example of the latter, I offer a phenomenon which has become frequent in the last decade or two but was unheard-of not long ago: Whatever used as a one-word conversational response. I am not sure when I first encountered this usage, though I am fairly sure it was after 1970. My own attempt to make explicit how it now functions, when the question arose in connexion with my work as a panelist for the Ask-a-Linguist public information service, was that it was a way of saying something like “You are such a loser that you mustn’t expect me to put effort into giving you a considered answer”. More recently, I read a journalist’s attempt to explicate the same usage; she understood it as something like “You are correct, but I am unwilling to admit it explicitly”. These glosses do not coincide but they have a family resemblance: they agree in interpreting the usage as expressing an attitude of scorn towards the conversational partner, while avoiding any commitment on the speaker’s part to a position distinct from the hearer’s.
The point relevant here is that (so far as I am aware) there was no previous recognized form of words that did quite the same job. If my or the journalist’s interpretations are correct, then one could have used similar wording to spell one’s attitude out explicitly – but the point of saying “Whatever”, as I understand it, is in large part to demonstrate one’s aloofness by making a minimal response: it would be uncool and defeat the object to say something in many words.
But although the usage was new, it was not an arbitrary invention, as if teenagers had decided to start saying Yonk, or Potato, to express their attitude. The fact that I could interpret the usage, at least approximately, stemmed from the fact that this new use of the word whatever has recognizable links to long-established uses of the word within fuller utterances. In the 1960s there was no known use for the word whatever in isolation, it was a word that would only occur as part of a few fairly specialized constructions; if I had been asked as a linguistics teacher at that period to give an example of an ill-formed English sentence, I could easily have suggested *Whatever. (The main reason why I probably would not have chosen that example in practice is not that I thought it might have a use, but that people who ask for examples of “starred sentences” are usually hoping for multi-word examples.) Yet although there was no recognized use for this utterance, someone, somewhere, found a use for it, hearers understood (at least roughly) what that person was doing with it, and it caught on. This was not most usefully seen, I suggest, as a change in the English language. It was the exploitation of a possibility that had been latent in the English language before anyone thought to use it.
Since Chomsky’s principle became influential in linguistics, it has often been pointed out how difficult it seems to be to identify specific word-sequences which one can confidently predict to be unusable. F.W. Householder (1973: 371) commented that it is necessary to “line up several articles and several prepositions in such examples, otherwise they become intelligible as some kind of special usage”. And before 1957 the concept of dividing the range of all possible word-sequences into well-formed and ill-formed subsets does not seem to have occurred in the linguistic literature. The asterisk notation which theoretical linguists now use to mark strings as ill-formed was adapted by them from a notation used by historical linguists to mean something quite different (historical linguists asterisk reconstructed forms to show that although they are postulated to have occurrred they are not actually attested). It is not clear to me precisely what Sapir meant by his famous comment “All grammars leak” (Sapir [1921] 1963: 38), but it would be difficult to interpret it in its context as a statement that every real-life grammar generates some set L' of strings which includes some strings that are not members of the target set L of well-formed strings and/or excludes some members of L – this idea of a language as a precisely-bounded set of strings simply does not seem to be present in the pages which lead up to the remark.
Statistics of construction frequencies
So far my discussion has been mainly conceptual and anecdotal. To make it more concretely empirical, let me introduce a piece of statistical analysis which replicates work I have discussed elsewhere (Sampson 1987) but using a larger, and probably more reliable, data-set. Figure 1, below, displays statistical properties of the alternative realizations of the high-frequency non-terminal category “noun phrase” in the SUSANNE treebank.[1]
SUSANNE comprises grammatical parse-trees for about 130,000 words of published American English, consisting of 64 files drawn from four genre categories of the Brown Corpus. The question addressed by the present analysis is: how diverse are the alternative realizations of a particular category, and in particular is there any objective evidence for a contrast between “well-formed” realizations that recur repeatedly thanks to their normative status, and one-off or rare “performance deviations”? The SUSANNE treebank is a good data-set to use in investigating this problem, being widely recognized as constructed with greater emphasis on consistency and predictability of annotation decisions than other comparable resources: for instance, Lin (2003: 321) comments that “compared with other possible alternatives such as the Penn Treebank … [t]he SUSANNE corpus puts more emphasis on precision and consistency”. There is some objective evidence (Babarczy et al. 2006, Sampson and Babarczy forthcoming) that the SUSANNE annotation scheme approaches the limit of humanly-possible grammatical-annotation precision. Thus, grammatical diversity in the SUSANNE treebank is likely to be genuine, rather than a product of inconsistent annotation behaviour by analysts. (The treebank used for the earlier analysis in Sampson (1987) was less than one-third the size of SUSANNE, and annotated at a period when the rigorous SUSANNE scheme was not yet fully developed, so that its annotation decisions may have been less consistent.)
My analysis examined the incidence, in Release 5 (2000) of the SUSANNE treebank, of various daughter-label sequences below mother nodes labelled as noun phrases. (Within the SUSANNE labelling scheme (Sampson 1995), this means nodes whose labels begin with the letter N, not followed by a second capital.) Noun-phrase nodes dominate sequences of one or more tagmatags (non-terminal labels) and/or wordtags.[2] Since the SUSANNE labelling system makes distinctions which are more refined than it is useful to include in this investigation, groups of related labels were merged by the following rules:
for tagmatags
tags beginning F… or T… (finite or non-finite
subordinate clauses) are reduced to that character and one
immediately-following lower-case character (thus e.g. relative clauses are
distinguished from nominal clauses, and infinitival clauses from
past-participle clauses)
tags beginning V… (verb group) are reduced to that character, followed only by i, g, or n if one of those characters appears in the unreduced tag (verb groups beginning with infinitives, present participles, and past participles are distinguished from finite verb groups)
all other tagmatags are reduced to their first character, followed only by q or v if one of those characters appears in the unreduced tag (basic tagma categories such as main clause, noun phrase, adjectival phrase, are distinguished from one another, and phrases including wh- or wh…ever elements are distinguished from non-wh- phrases)
for wordtags
tags beginning V… (verbs) include all capital
letters in the unreduced tag (grammatically-distinct verb forms are
distinguished)
other wordtags are represented by their first two letters, together with the characters 1, 2, and/or Q if these appear in the unreduced tag (parts of speech are distinguished, and explicitly singular or plural forms, and wh- forms, are marked as such)
The consequence of this label simplification is that the vocabulary of labels found in daughter sequences below the 34914 SUSANNE noun-phrase nodes comprises exactly one hundred elements: 29 distinct tagmatags, and 71 distinct wordtags.
Various sequences of elements drawn from this vocabulary occur with different frequencies as daughter-sequences of noun-phrase nodes. Thus, the commonest and second-commonest expansions of the category “noun phrase” are PP1 (singular personal pronoun – 3749 instances) and AT NN1 (the or no followed by singular common noun – 2605 instances); at the other extreme, 2904 distinct daughter-sequences are each represented once in the data (an example is NP1 NN1 YC Fr, singular proper noun + singular common noun + comma + relative clause, the SUSANNE instance being Fulton County, which receives none of this money A01:0370). Figure 1 plots the various frequencies observed (expressed as average words of text per instance of a daughter-sequence) against the proportion of noun-phrase tokens in the data that represent types of that or a lower frequency. Thus, the leftmost data-point in Figure 1 is at (35.0, 1.0): 3749 instances of the noun-phrase type PP1 in the 131302 words (not counting punctuation marks) of SUSANNE is one per 35.0 words, and since this is the highest frequency in the data, all noun phrases in SUSANNE belong to types of that frequency or less. The rightmost data-point is at (131302, 0.083); 8.3% of SUSANNE noun-phrase tokens (i.e. 2904 out of 34914, or one in twelve) belong to types occurring just once each in the treebank.
Figure 1
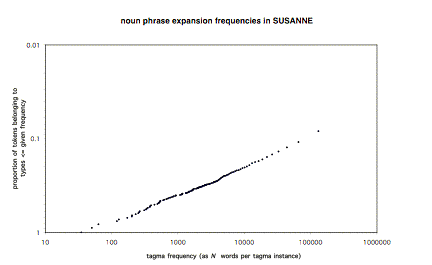
The significance of Figure 1 lies not just in the fact that on a log–log scale it is linear, without notable discontinuities, but in the shallowness of the slope. Although the data-points towards the right represent low frequencies for particular label-sequences, so many different types of label-sequence occur with those low frequencies that the proportion of all noun-phrase tokens accounted for by low-frequency types is quite high.
The trend line to which the data-points approximate is y = 3.1x–0.3. If this linearity were maintained in larger samples of text, permitting lower frequencies to be observed than is possible with SUSANNE (where the lowest observable frequency is one instance in 131302 words), then substantial proportions of noun-phrase tokens would be accounted for by types of truly minute frequencies. One in twenty noun phrases would represent types occurring not more than once in a million words. One in 160 or so noun phrases would represent types occurring not more than once in an American billion (109) words. One in 1300 noun phrases would represent types occurring not more than once in 1012 words.
In other words, constructions too individually rare for their existence to be reliably confirmed by observation would collectively form too large a proportion of what happens in the language for a grammatical description which ignored them to be satisfactory.
Many of the one-off constructions in SUSANNE, such as the example quoted above, are clearly “normal” although they happen not to recur within this data-set. But there are others where low frequency seems to correlate with oddity. Consider for instance the daughter-sequence AT S NN1 YC S, that is the or no + main clause + singular common noun + comma + main clause. Is that sequence a valid way to realize the category “noun phrase”? Considered in the abstract one might well feel confident in saying no. But now look at the SUSANNE instance (I show preceding context within square brackets): [One can meet with aloofness almost anywhere:] the Thank-Heaven-We’re-not-Involved viewpoint, It Doesn’t Affect Us! G17:0680. The oddity of the tag sequence turns out to stem largely from the way in which a quoted sentence being used to modify the noun viewpoint has in part been postposed after that noun. Before I read this example, I am not sure that I would have been alive to the possibility of realizing an idea like this in quite that way (just as I was not aware of the possibility exemplified by the Mortimer example quoted earlier before I read his novel); but now that I see the SUSANNE example, I cannot regard it as “wrong”. It was written by an English native speaker, and I as another English native speaker understand it perfectly well; furthermore, I understand and sympathize with the writer’s motive in postposing the second quoted clause (if the entire quotation were included in the ordinary modifying position before viewpoint, a reader could easily lose the thread before reaching the point at which he discovered that the long quotation was functioning as a modifier to a following noun). This seems to be an example of what I shall call a “Dunster construction”: a construction which before I encountered it I would not have thought of as available in my language, but which after confronting a real-life example I come to see as a valid possibility which had been available to me all along. It is not likely that the leftmost parts of Figure 1 contain Dunster constructions (if a construction recurs often enough, a speaker of the language will surely recognize it); but the right-hand side of Figure 1 includes some Dunster constructions alongside clearly normal constructions.
A range without boundaries
The picture I take from Figure 1 is that the grammatical possibilities of a language are like a network of paths in open grassland. There are a number of heavily used, wide and well-beaten tracks. Other, less popular routes are narrower, and the variation extends smoothly down to routes used only very occasionally, which are barely distinguishable furrows or, if they are used rarely enough, perhaps not even visible as permanent marks in the grass; but there are no fences anywhere preventing any particular route being used, and there is no sharp discontinuity akin to the contrast between metalled roads and foot-made paths – the widest highway is only the result of people going that way much more often and in far greater numbers than in the case of narrow paths.
I do not say that, for a given language, there are no word-sequences which genuinely will never find a use. I am not claiming that every member of the set of all possible strings over the vocabulary – or even, every member short enough to be utterable in practice – will sooner or later acquire some communicative function. It may be that some never will, even if the language continues to be spoken indefinitely. That would mean that instead of one boundary, between grammatical and ungrammatical sequences, there might in principle be two boundaries: (i) a boundary between the set of sequences which feel familiar to a speaker, and the set of sequences which are unfamiliar either because they include Dunster constructions or because they will never have any use; and (ii) a boundary between sequences destined never to have a use, and those which will in due course be useful.
But boundary (ii), between those word-sequences which are destined never to have a use, and those which have not found a use so far but will do so at some time in the future (whether we are discussing the language of a community or that of an individual speaker), is an unknowable thing, as inaccessible to scientific enquiry as questions about what technological inventions will be made in future (if we knew precisely what invention would be made next year, we would have made it today). And boundary (i), between the word-sequences for which an individual, or a language-community, has already found a use, and the sequences which have not come into use yet but are destined to do so in due course, while it might be scientifically checkable (though to do so accurately for the more marginal constructions would require an impractically comprehensive range of observations), is a purely contingent thing of no real scientific interest. If the only reason why I have not been saying things like as I have made it clear is that before reading Mortimer I had not realized that it is as compatible with the norms of my language as the alternative as I have made clear, then plotting the boundary between things a speaker does say, and things he has not said yet but will, would in effect mean listing a long series of chance pieces of linguistic experience. It would be as tedious as listing what a man was given to eat each time he visited friends for dinner; it would just be a set of contingent facts, with little system or principle underlying them.
Frederick Newmeyer (2003) has argued that “grammar is grammar and usage is usage”: the two are different and not to be confused. In a sense I agree with Newmeyer: a description of usage, whether an individual’s usage or that of a wider speech-community, does not define a grammar in his sense of the word. But I would add that grammar in Newmeyer’s sense is a fiction. Usage is a reality in the world, which can be described more or less accurately, but there is no separate reality corresponding to Newmeyer’s “grammar”.
How might a defender of the distinction between normal and deviant (or “grammatical” and “ungrammatical”) strings hope to justify that distinction, if constructions occur at a range of frequencies which vary smoothly down to a lowest observable level where clearly-normal constructions are mingled with Dunster constructions? Would anyone argue that the problem will be solved by enlarging the data-set? Since my analysis here is based on the largest extant data-set which I believe to be adequately accurate, I must concede that it is logically possible that a very much larger body of data, enabling substantially lower frequencies to be registered, could show a discontinuity in the distribution of construction-frequencies, with a gap between the range of “normal” constructions and a scattering of much-lower-frequency deviant constructions. But the analysis of Sampson (1987), based on a 40,000-word sample, gave a linear plot. SUSANNE more than triples the quantity of wording and gives an equally linear plot. I venture the prediction that, no matter how far the database is expanded, the statistics corresponding to Figure 1 will continue to be about equally linear. (As a matter of fact, although my earlier analysis in Sampson 1987 has been criticized, by Taylor et al. 1989, Briscoe 1990, and Culy 1998, these critics do not appear to have made or suggested a prediction contradicting the one I have just offered.)
Clearly, other linguists might well disagree with the particular scheme for annotating grammatical structure from which the data in Figure 1 are derived. A linguist might urge that the one hundred symbols into which the SUSANNE label-set has been collapsed make too few distinctions in some areas, and/or too many (irrelevant) distinctions in others – and not just the limited alphabet of 100 symbols, but the far larger range of symbols in the full SUSANNE scheme, might be criticized in similar ways. Not only the label-set, but the shapes of the SUSANNE trees (and hence the identity of the word-sequences which are recognized as constructions), may be called into question; generative linguists tend to draw much “deeper” trees than those assigned by the SUSANNE scheme to given sentences, i.e. their analyses recognize more constructions per sentence and their constructions on average have fewer daughters. I would be the first to agree that the analytic scheme from which Figure 1 derives is not to be seen as “the right scheme” for annotating English grammar – I myself am sceptical about the concept of a single “right” scheme. If the SUSANNE text-samples were re-annotated in conformity with some other analytic scheme, the shape of Figure 1 would change.
But although numbers derived from a re-annotated treebank would certainly differ in detail from those of Figure 1, again my prediction would be that for any reasonable analytic scheme (any scheme that was not deliberately gerrymandered to give a contrary result with the SUSANNE text-samples) the significant features of Figure 1 would be unchanged: the new plot would continue to show data-points distributed smoothly and approximately log-linearly along a gentle slope. This is a fallible hypothesis, of course, as scientific statements should be; but at present I do not have the impression that this is a direction in which critics see my position as vulnerable.
I realize also that those who believe in a clearcut grammatical/ungrammatical contrast make no claim that grammatical constructions all occur with equal or even similar frequencies. Many of them would emphatically reject that idea. Presumably they would say that ill-formed constructions occur only at frequencies substantially lower than those of the commonest well-formed constructions (this is not a point which I have seen discussed in the literature, but it is unclear to me what it could mean to describe some of the most usual turns of phrase in a language as not well-formed in that language – unless “not well-formed” meant “unacceptable in high-prestige discourse”, which is not the sense relevant here). But saying that ill-formed constructions are less common than the commonest well-formed constructions is compatible with saying that different well-formed constructions occur at very different frequencies, with some being fully as rare as the ill-formed structures that occur as sporadic performance errors. Indeed, a linguist who favours a scheme of analysis which yields “deeper” trees than the SUSANNE scheme, so that constructions which SUSANNE treats as minimal subtrees (pairings of a mother node with a set of immediately-dominated daughter nodes) have various intermediate nodes in the favoured analysis, might suggest that fractional probabilities attached to individual production rules would have to be multiplied together to give very low probabilities for those SUSANNE constructions which comprise many intermediate nodes in the favoured analysis, so that one would expect various SUSANNE constructions to occur over a wide range of frequencies extending down to very low ones. (The criticisms listed above of my 1987 paper each included comments along these lines.)
But if one reconciles data like Figure 1 with the grammatical/ungrammatical distinction in this way by saying that grammatical constructions alone occur at many different frequencies, and the lower areas of their frequency range include frequencies at which various types of performance deviation also occur, then the question arises how someone constructing a grammatical description is to distinguish between well-formed but rare constructions, which the grammar should generate, and performance deviations, which it should exclude? What evidence could this distinction be based on? How could one hope to argue that one particular grammatical description of a language was more or less accurate than another?
Can intuition substitute for observation?
A number of linguists would answer the question about how we are to establish a grammatical/ungrammatical distinction by arguing that it is not a matter of observed frequencies at all, but a matter of what speakers of a language know qua speakers to be allowable versus deviant – a matter of “introspection” or “speaker intuition”. Andrew Carnie, whom I quoted in my introduction, writes (2002: 11) that as grammarians “we have to rely on our knowledge of our native language (or on the knowledge of a native speaker consultant for languages that we don’t speak natively)”, eliciting this unconscious knowledge via “grammaticality judgment task[s]”. Terence Nunnally, reviewing a corpus-based account of one aspect of English grammar, puts the point specially forcefully (2002: 177): “it is intuition that signals ill-formedness, not frequency of formations per million words”. Frederick Newmeyer (2003: 689–92) makes various claims about judgements which he claims English-speakers can make introspectively, independently of experience, about what can and cannot be said. Linguists have been making similar comments since the beginning of the generative movement. Sometimes they have claimed that speakers have introspective or intuitive access to aspects of grammar extending far beyond the fundamental issue of whether given word-sequences are well- or ill-formed; in an early textbook, Terence Langendoen (1969: 9–11) claimed that fluent speakers not only can do this but can identify the parts of speech to which the words of a well-formed sentence belong, and the constituent structure into which those words fit.
It is startling to find 20th- and 21st-century scientists maintaining that theories in any branch of science ought explicitly to be based on what people subjectively “know” or “intuit” to be the case, rather than on objective, interpersonally-observable data. Surely we would think it strange if, say, physicists based their laws of motion on the fact that they “knew” without experiment that balls of different weights released from a tower simultaneously would hit the ground at the same time, or “knew” that they would hit at different times (and we would think it even stranger if they ignored contrary experimental findings as irrelevant).[3] But language is an aspect of human behaviour while the motions of inanimate objects are not, so there is perhaps superficial plausibility in the idea that people might have access to reliable intuitions about their native language, whereas no-one today would claim reliable intuitive knowledge about the laws of motion. However, plausible though the former idea might be to some, it is obviously wrong.
The chief flaw in it is not the fact that different individual speakers of the same language regularly differ when asked about the grammaticality or well-formedness of particular strings of words – though the fact that they do is by now so well-known that it is not worth quoting examples here. That could reflect merely the fact that individuals induce slightly different sets of rules when exposed during childhood to different finite samples of the same language. Wayne Cowart (1997) has shown us that the chaotic appearance of an individual speaker’s grammaticality judgements may be misleading: one can sometimes tease out systematic patterns underlying the apparent chaos. The real issue is that there is no reason to assume that patterns in a speaker’s intuitive grammaticality judgments reflect realities of his language.
There are plenty of other factors which they may reflect. The realities of some other, socially significant dialect or language can often give a speaker false intuitions about his own usage. (Consider for instance William Labov’s discussion (1975: 34–6) of Philadelphia speakers who insisted, with every appearance of sincerity, that they had not encountered “positive any more” sentences such as John is smoking a lot any more, and had no idea how to interpret them, yet were observed to use the construction themselves in the way that is normal for their dialect area though it does not occur in general American English.) Speakers’ linguistic intuitions may be heavily moulded by a tradition of teaching the national language which happens to be erroneous in various respects (as schoolroom teaching about the English language for centuries misrepresented it in terms of models based in part on Latin and on Hellenistic Greek rather than on English itself). A speaker who is an academic linguist may unconsciously permit his intuitive response to examples to be moulded by the desire to produce evidence supporting and not disconfirming his grammatical theories; it was cases where this seemed to have happened that led Labov to urge ([1970] 1978: 199) that “linguists cannot continue to produce theory and data at the same time”. Indeed, a speaker’s linguistic intuitions can in some cases be controlled by some purely private, and mistaken, theory which that speaker has formulated. I have discussed elsewhere (Sampson 2001: 140 n.1) the case of a computing engineer who believed that the English a/an alternation rule implied the choice of an rather than a before e.g. good egg – he realized that the choice depended on whether a later word began with vowel or consonant, but he wrongly believed that the relevant word was the noun rather than the immediately-following word, where these are not the same. (He surely had not heard people regularly saying things like an good egg.)
It may be that many speakers do have reasonably accurate intuitions about at least the high-frequency, “core” constructions of their language. But even if that were true, it would not help theoretical linguists much, because their controversies tend to turn on the grammatical status not of straightforward core examples but of unusual word-strings which would probably be infrequent in practice even if “grammatical”. One could argue that whereas intuitive methods might often have been satisfactory in practice for linguistics in the pre-generative period, when the grammatical phenomena discussed were commonly high-frequency ones for which speakers’ intuitive judgements may be accurate, generative syntactic research has a much greater need of corpus or other empirical data, because speakers cannot be expected to make reliable judgements about the status of the unusual word sequences which are often crucial to its theoretical debates.[4]
And in any case, the only way that we could ultimately know speaker intuitions to be reliable, even with respect to core usage, would be to check a language-description based on intuitions against one based on empirical observation. But, if we had the latter, the former would be redundant and uninteresting.
How intuitions have misled
It is understandable that grammarians of the 1960s and 1970s made heavy use of subjective intuition, because before the widespread availability of computers and language corpora it was often quite difficult in practice to gather relevant empirical data. In such circumstances it might perhaps be scientifically respectable to base theories on impressionistic data (provided that it was made explicit that such theorizing was provisional and liable to reconsideration as better data became available). But linguists’ intuition-based claims were often so extravagant that one suspects those making the claims cannot have realized how soon advances in technology were destined to make it easy to check and refute them.
One example that I have discussed elsewhere (Sampson 2005a: 71–2; 2005b: 18–19) is a claim made originally by J.R. (“Haj”) Ross in a 1974 lecture, following which it was reasserted by Aronoff (1976), by Roeper and Siegel (1978), by Carlson and Roeper (1980), and (according to Laurie Bauer (1990)) by others since. The claim is that if a verb in English has a prefix it cannot take a non-nominal complement; various of the linguists cited developed subtle grammatical theories in the attempt to explain this “fact”.
There is a story that when Charles II founded the Royal Society, he asked its scientists to explain to him why a pail of water does not become heavier when a live fish is added to it. After the scientists eventually confessed themselves baffled, the king roared with laughter and pointed out that in fact the pail does become heavier. Ross’s “fact” is one of a similar order. Bauer points out that it is perfectly normal for prefixed verbs, such as overindulge or reaffirm, to take prepositional-phrase or clause complements, contrary to the claim spelled out quite explicitly by Carlson and Roeper (1980). It is not necessary to resort to a formal linguistic corpus to check this: a few seconds with Google yields plenty of examples. Here are a few that I found on 17 Oct 2005:
If you tend to overindulge in tasty, high-sugar and fatty foods, try the Raw Food or Macrobiotics diets.
I want to overindulge in you.
The only way to be happy is to overindulge in food and drink.
His fellow monks thought he’d overindulged in turnip wine when he told them about it.
New rules reaffirm that it is illegal to give out state secrets on the Internet.
New U.S. Geological Survey (USGS) science reaffirms, with strong genetic evidence, that the northern spotted owl is a separate subspecies from California and Mexican spotted owls.
We recognised that maintaining this growth is a challenge, and reaffirmed that each of our countries must play its part to support long-term sustainable growth.
The U.S. side reaffirmed that the U.S. has always been open to dialogue in principle.
How would a believer in intuition-based linguistics respond to a case like this? I take it that he would not argue that the various Google quotations represent ungrammatical “performance deviations”. They made sense to the writers, they make sense and feel normal enough to me (and, I suspect, to my present readers); why should we agree to classify them as “deviant”, merely because a number of linguists said that such constructions do not occur in English? Can anyone announce off the cuff that some ordinary-looking construction is ungrammatical, and are we under some obligation to agree? Surely no-one would go as far as that.
But if a defender of intuition says that in this case Haj Ross, and the various linguists who repeated his claim, were mistaken, then the obvious question arises as to how we distinguish between reliable, veridical linguistic intuitions and mistakes. It is not, evidently, that occasional mistakes are made by individual linguists in the heat of the moment but once an intuitive claim is considered and reaffirmed over a period by a range of linguists it becomes veridical; the latter did happen in this case.
Elsewhere (Sampson 2002: 79–90; 2005a: 45–7, 79–89) I have discussed a particular grammaticality issue, relating to English questions in which a subordinate clause precedes the main clause, which could well be the most frequently-considered single grammatical phenomenon in all of modern theoretical linguistics. Pullum and Scholz (2002: 39) cite eight places where it is discussed by Noam Chomsky, at dates ranging from 1965 to 1988, and they give a (non-exhaustive) list of eight examples of other linguists who have discussed it in publications at different dates in the 1990s. If intensive attention makes linguistic intuitions veridical, intuitions about this particular phenomenon should certainly be so. Yet Pullum’s and my intuitions about the facts were different from those of Chomsky and other linguists who align themselves theoretically with him; and, when I used corpus data to check the facts of usage, I found that these were systematically different both from what Chomsky predicted and from what Pullum and I predicted.
Briefly, before any parties had examined corpus data, Chomsky believed that English questions in which a subordinate clause precedes the main clause, while grammatical, were vanishingly rare in real-life usage (“you can go over a vast amount of data of experience without ever finding such a case”, Piattelli-Palmarini 1980: 115); and many other generative linguists had concurred with this. Pullum, and I, believed that such questions were quite common in everyday usage. But when I investigated the issue empirically, using both the written-language and the demographically-sampled speech sections of the British National Corpus, a more complex pattern emerged.[5] There are two subclasses of question meeting the description just given: (i) questions in which the subordinate clause precedes all other parts of the main clause, e.g. If you don’t need this, can I have it?, and (ii) questions in which the subordinate clause occurs within the subject of the main clause, e.g. Will those who are coming raise their hands? It turned out that questions of type (i) are frequent both in spontaneous speech and in writing, while those of type (ii) are frequent in writing but appear not to occur at all in spontaneous speech. (If those are the facts of usage, for me there is no separate issue to be addressed about whether either or both types of question are “grammatical”; what Chomsky’s, or Pullum’s, position on that would be is for them rather than for me to say.)
The fact that empirical corpus data can so straightforwardly contradict both sides of such an intensively-canvassed grammatical controversy is impressive confirmation of the danger of relying on “speaker’s intuition”.
If intensity of discussion is no guarantee of reliability of linguistic intuitions, would it be said that reliability is to be assessed in terms of the standing of the linguist whose intuitions they are? According to Labov (1975: 28–30), Chomsky’s writings sometimes imply that Chomsky’s own intuitions are veridical linguistic data while those of other linguists are only fallible opinions. But surely no-one, Chomsky included, would seriously and openly put this forward as a principle for assessing linguistic data.
Whether or not he did believe that certain speakers’ linguistic intuitions have an authority lacking in the intuitions of others, Noam Chomsky, like Terence Langendoen, held a relatively broad view of the categories of linguistic fact to which intuition gives us access. For him, these were not limited to the grammatical status and the occurrence or non-occurrence in mature speakers’ usage of particular strings of words. He repeatedly claimed to know, without examining evidence, features of the patterns of errors made by children on the way to becoming mature language users. In connexion with the grammaticality issue alluded to above (the fact that a question containing a subordinate clause preceding the main clause is formed by fronting the main verb rather than the verb of the subordinate clause), Chomsky wrote “Children make many mistakes in language learning, but never mistakes such as [a question with the wrong verb fronted]” ([1975] 1976: 31); “It is certainly true that children never make mistakes about this kind of thing” (Piattelli-Palmarini 1980: 114). Yet in reality even adults make occasional mistakes about the issue Chomsky is discussing. In October 1999 I listened to a 51-year-old monoglot Englishwoman (with no knowledge of or interest in linguistics) telling me that one of the good things about her voluntary work as an ambulance driver was that she never had to ask herself:
Am what I doing is worthwhile?
This is precisely the question structure which Chomky believed children never produce even as a mistake of inexperience; the fact that such a thing can evidently be uttered by a mature speaker seems to establish that such matters cannot be decided in terms of what anyone thinks is “certainly true”, but only in terms of observation.
The fact is that linguists who want to treat speakers’ intuitions rather than interpersonally-observable evidence as the basis of linguistic description are simply choosing to turn their back on science, and reverting to the pre-modern pattern of “arguments from authority”. Up to the early modern period, people “knew” that the Sun goes round the Earth. The Pope and other leaders of the Church proclaimed it, and Giordano Bruno was burned at the stake partly because he held a different opinion. If one’s priority is to have fixed theories which everyone accepts, this may be an efficient approach to achieving them; but what the 17th-century development of the scientific method showed us was that as a way of arriving at truth it was severely unsatisfactory. If linguistics is to be taken seriously as a knowledge-generating enterprise, it simply must base itself on empirical, interpersonally-observable data. And if it does so, I question whether it will give us a basis for drawing a distinction between “grammatical” and “ungrammatical” word-strings.
Is English special?
One way in which the point of view advocated here might be criticized would be by arguing that it is unduly influenced by the fact that the author’s native language happens to fall close to the isolating extreme of linguistic typology. We have seen that Householder commented how difficult it is to line up English words in a way that cannot be assigned any sense at all; but arguably it is easier to do this for a language with a richer inflexion system. In Latin or French, for instance, one can produce clearcut ungrammaticality by violating gender agreement between adjective and noun, or person and number agreement between subject and verb.
Even English has some rules as categorical as this. A third-person singular verb form should not take a first- or second-person subject; or, consider the word-order rule cited against me by Christopher Culy (1998), that a definite article precedes rather than follows the noun with which it is in construction. I agree that I can find no case of the following its noun in the hundred million words of the British National Corpus.
In responding to Culy (Sampson 2001: 177), I suggested a contrived but, I believe, realistic situation in which the would occur after its noun in a meaningful English utterance: describing a foreign language, one might easily say something like Norwegians put the article after the noun, in their language they say things like bread the is on table the. Describing how other languages work is one valid use of a language, alongside innumerable other uses, so this response to Culy’s objection was fair. And I believe it might be possible to construct comparable scenarios in which it would be natural to utter sentences of a more highly inflected language with violations of the normal rules governing inflexions – though as the number of such violations was increased, no doubt the scenarios in which the resulting utterances might occur would quickly become very tortuously contrived indeed.
However, I do not want to press this defence of my thesis. Ultimately I believe one can sustain the strong claim that there is no well-defined contrast between grammatical and ungrammatical, but many readers will find a resort to scenarios where one language is used to imitate the structure of another to be an unsatisfactory, almost cheating way of shoring up that claim. I share this instinctive reaction.
So let me concede that word-sequences containing violations of inflexional agreement rules, or of word-order rules as fundamental as the English rule that the definite article precedes its noun, do have a status distinct from the kinds of word sequence which speakers commonly use in discussing everyday topics other than language itself. I would be willing to accept the term “ungrammatical” to describe those abnormal sequences.
Even with this concession, though, I believe my position on “grammaticality” remains very distinct from the standard generative linguists’ position. Linguists who understand grammatical description in Chomsky’s terms as partitioning the set of all strings over the vocabulary of a language into two subsets, a grammatical and an ungrammatical subset, do not usually (it seems to me) think of the grammatical subset as comprising all strings other than those which contain oddities as striking but superficial as an agreement failure, or (in the English case) a definite article following its noun. That would be a thin, impoverished concept of grammar, relative to the concept which has motivated the large volume of effort that has been devoted to generative grammatical analysis over fifty years. Surely, linguists have been assuming that there are contrasts between well-formed and ill-formed also with respect to the larger syntactic architecture of clauses and sentences: for instance, with respect to the positions in a matrix clause where it makes sense to introduce a subordinate clause.
Whether a language is of isolating or inflecting type does not seem very relevant to those “architectural” aspects of sentence structure. It is with respect to them that I am mainly aiming to deny that the grammatical/ungrammatical contrast is a real one.
The analogy with word meaning
Let me try to make the view of grammar I am advocating more palatable, by drawing an analogy with another area of natural language where the corresponding point of view may be less controversial: namely, word meanings.
Grammar is about which assemblages of words have uses in a language. Semantics is about how one can move inferentially from one usable word-sequence to another. What it means to say that an English speaker knows the meaning of the word father, for instance, is that he is capable of drawing various inferences involving that word: e.g. from the statement this person is my father he can infer this person is male.
That suggests a scenario in which someone who masters a language has access to a fixed set of inferential relationships among its sentences. With a logical system such as the propositional calculus, that is very much what mastery implies: for any particular set of its well-formed formulae, taken as premisses, there is some particular set of well-formed formulae which can be derived as conclusions from those premisses, and someone who learns the system will be more or less capable of working out which they are in particular cases. But if there is one point on which philosophers of the later 20th century came to agree, at least in the English-speaking world, it is that natural languages are not like that. The point was usually argued in terms of the limiting case, where the premiss-set is of size zero. In a logical system, for any set of N premisses there is some set of valid conclusions, and in particular there are certain well-formed formulae which can be obtained as valid conclusions from the empty set of premisses: those formulae are called “theorems” of the system. In a natural language, one speaks of “analytic statements” which are true by virtue of their meaning (that is, they can be inferred from the empty set of premisses), versus “synthetic statements” whose meaning does not give us their truth-value – we need one or more factual premisses before we can establish whether a synthetic statement is true or false.[6] Thus one might see My father is male as an analytic truth of English, whereas This person is male would be either a synthetic truth or a synthetic falsehood.
From the Second World War onwards, a central preoccupation of English-speaking philosophy (I believe it would be fair to say “the central preoccupation”) was language, and the central point about language as actually used in everyday life (“ordinary language”) was that there is in fact no distinction between the analytic and the synthetic: language and the realities it is used to describe are both so fluid that it is impossible to allocate particular statements to one side or other of the analytic/synthetic boundary. (If one feels that it is safe to describe My father is male as necessarily true by virtue of its meaning, what does one say about a case where a man fathers children and then changes sex, for which there are plenty of precedents nowadays? Uttered by the children, the statement is a falsehood. I discuss this example more fully in Sampson 2001: 195–7.)
Philosophers usually discussed the issue in terms of the limiting case of analytic versus synthetic statements, but the point they were making was more general: a natural language does not embody fixed inference relationships between its statements, such that from a given set of N natural-language premisses (whether N is zero or a larger number) there is some definite set of conclusions which can be validly drawn from them. Properties flick unpredictably between being defining features of a word and being merely contingently associated with that word, as an individual’s or society’s experience develops: the advent of sex-change operations changed masculinity from a defining feature of fathers to a very highly-probable correlate. To quote Ludwig Wittgenstein (1953: 37e–38e), “what to-day counts as an observed concomitant of a phenomenon will tomorrow be used to define it.”
In Britain the leading proponent of this view was Wittgenstein, whose ideas dominated British philosophy in the 1950s, 1960s, and 1970s with few rivals. In the USA, essentially the same view was argued independently by Willard Quine (1951) and Morton White (1950), and again their position was accepted with very little disagreement. In the closing decades of the century philosophers’ attention tended to shift away from language to other topics, but that did not mean that the discipline had changed its mind about the analytic/synthetic distinction – a new generation simply found it more worthwhile to study areas such as ethics or politics rather than language, but they did not contradict what their predecessors had said about language. Indeed, refutation of the analytic/synthetic distinction in ordinary language is arguably an unusually clear counterexample to the frequently-heard complaint that philosophy is a subject where little real progress is made and the same ranges of alternative answers to the same questions continue to be canvassed down the centuries. Since the mid-20th century, we have understood how meaning in natural language works better than people understood it before.
If the reader accepts that the idea of fixed inference-relationships between natural-language sentences, while perhaps superficially tempting, must in fact be given up, he may find it easier to accept the analogous point that in the domain of grammar the idea of a fixed set of well-formed or “grammatical” sentences may be intuitively appealing but is in reality a delusion. Earlier in my own career I accepted Wittgenstein’s and Quine’s arguments against the analytic/synthetic distinction, but I believed that grammar was different: I supposed that there really is a well-defined set of valid English sentences, although definite rules prescribing how we can move inferentially among them do not exist. More recently, I have come to see the grammatical/ungrammatical distinction as resembling the analytic/synthetic distinction: they are inventions imposed without scientific basis on intrinsically fluid realities.
It should be said that there have been generative linguists who have discussed word-meaning in a fashion which implies that Wittgenstein and Quine were wrong on the analytic/synthetic issue. The earliest, and for years the most influential, generative-linguistics publication on meaning was Katz and Fodor (1963). But Katz and Fodor began by simply rejecting the possibility of a connexion between linguistic accounts of meaning in language and philosophers’ discussions of the subject:
Philosophical inquiry into the meaning and use of words has neither drawn upon nor contributed to semantic investigation in psychology and linguistics. Correspondingly, accounts of meaning proposed by linguists and psychologists cannot in any obvious way be connected with theories current in philosophy or with one another.
And Katz and Fodor went on to develop a formal theory of word-meaning which treats the definitions in ordinary published dictionaries such as the Shorter Oxford English Dictionary as definitive accounts of the meanings of the respective words (although it is unlikely that the lexicographers responsible for compiling the dictionaries would make such large claims for the nature of their work), and which among other things implies that the class of analytic sentences, such as Bachelors are unmarried, is well-defined. Katz and Fodor (1963) were less concerned with the analytic/synthetic distinction than with formalizing ways in which word-ambiguities, e.g. between bachelor as unmarried man and bachelor as holder of a university degree, are resolved in context; but Katz (1964) argued that their theory actually offered a “solution to Quine’s problem” about analyticity. However, Katz showed only that, if the Katz/Fodor formalism were accepted as capable of accurately representing meaning relations in English, then it provided a clearcut formal distinction between analytic and synthetic sentences. Katz (1964) entirely missed the point that, if Quine was right, no formalism akin to those of Katz and Fodor (1963) could accurately represent meaning relations in a natural language.
An attack which goes as wide of the target as that surely cannot be taken as a serious rebuttal of an established position. And, although some linguists have continued to discuss word meanings within the generative framework since that early period, so far as I have seen these discussions have paid little heed to earlier ideas about the topic, including ideas about how constantly evolving realities and human knowledge of realities prevent a natural language from having fixed meaning relations between words. I have seen nothing in the literature of linguistic semantics which leads me to doubt Wittgenstein’s and Quine’s view of inference in natural language as too fluid and unpredictable to be described by fixed rules (though the reader must decide for himself whether or not I am underrating that literature). If the Wittgenstein/Quine view of word meaning is right, then it is surely at least plausible that “grammaticality” in natural language is similarly ill-defined.
Grammar as an expression of logical structure
Formal logic is relevant to our topic in a further way, relating to “structural meaning”as opposed to “word meaning” – i.e. to those aspects of meaning which in a natural language are expressed by the ways words are grouped together into larger structures, and by inflexions and closed-class “grammar words”, as opposed to open-class content words such as nouns, verbs, and adjectives. One factor helping to explain the plausibility of the view that grammaticality is a well-defined property of word sequences is that many people see natural languages as irregular and sometimes cumbersome or imperfect devices for realizing, through the medium of speech-sound, structures of meaning which are given in advance of the evolution of particular natural languages and are common to all mankind – whether because they are a matter of logical necessity, independent of human thought (Bertrand Russell seems to have envisaged natural languages in these terms, cf. Russell [1957] 2001: 245), or because the meaning-structures form a Universal Grammar which is part of the genetic endowment of our particular species even though, logically speaking, other grammars would be possible.
If it were true that natural-language utterances were tools for expressing logical structures which were independent of particular languages, then I agree that it might follow that within any one natural language there would be a distinction between word-sequences which are the conventional expression of some formulae of the universal logic (and are therefore grammatical), and word-sequences which do not conventionally correspond to any formula of the universal logic (and are therefore deviant). The only grey areas would relate to cases where the conventional method of expressing a logical formula changed, or differed from person to person; there would be no cases akin to Whatever! where speakers would bend language to express novel meanings – if the logic of language were determined by our genetic inheritance, or even determined independently of our species by eternal principles, comparably to the way that the distribution of prime numbers is determined, then there could be no possibility of individuals developing grammatically-novel meanings.
But this way of thinking about meaning in natural language is grossly unpersuasive. It is very difficult to argue that natural-language grammars are naturally-evolved and imperfect devices for expressing sense structures which the formulae of mathematical logic express in a more direct and perfect way, for one thing because it is noticeable that many sense-distinctions which are basic to numerous natural languages have no equivalent in standard formal logics. To take just one instance, every natural language that I am familiar with has an important contrast between words corresponding to English and versus but; yet in the propositional calculus, and the more refined logical calculi which build on that, and and but translate indifferently into the same conjunction symbol. Both in terms of history (natural languages came first) and in terms of the comprehensiveness of the meaning-categories expressed, it is more reasonable to see formal logical systems as partial attempts to capture meaning in the natural languages native to those who developed the logical systems, rather than vice versa.
And the idea that a specific logical system is genetically fixed in our species cannot be taken seriously either, because it is clear that relevant properties of natural languages are culture-specific and vary over time. Some linguists in recent decades have suggested that natural languages do not differ from one another in the range of logical structures they can express (for instance, Ray Jackendoff claimed (1993: 32) that “the earliest written documents already display the full expressive variety and grammatical complexity of modern languages”); but that is simply not true. Modern European languages may be interchangeable in that way, but then their speakers are heirs to a great deal of common intellectual history. If we look further afield in time or space, we find very significant variation. Guy Deutscher (2000) has shown that complement clauses evolved within a particular ancient language that previously lacked them, namely Akkadian, after that language had already been reduced to writing. Dan Everett (2005) has described a language spoken by a remote South American tribe in our own time, Pirahã, which entirely lacks clause subordination of any kind, and contrasts with European languages in other fundamental semantic respects also, for instance it lacks any method of expressing quantification. If linguistics has been slow to grasp how different from one another natural languages can be in terms of the ranges of logical structures which they encode, part of the explanation is provided by David Gil (e.g. 2001), who shows, in the case of Malay/Indonesian, how the high-prestige variety of the language whose structures map fairly closely onto those of European languages, and which is thought of by present-day speakers as their “real” language, is structurally rather different in kind from lower-prestige varieties which the same speakers actually use spontaneously in ordinary life. If an exotic-language informant gives a Western linguist a picture of his language that makes it seem to be just an alternative system of coding conventions for expressing more or less the same range of meanings as a European language, this may often be because the informant is responding to the linguist’s elicitation questions by using an artificial variety of his language which has been developed under the influence of European languages.
Not only do natural languages differ with respect to the systems of structural meaning which they encode, but individual speakers of a language may well differ in the extent to which they master the range of logical possibilities provided by that language. Ngoni Chipere (2003) has begun to investigate differences between individuals with respect to their ability to deal with grammatical complexity.
The most influential current proponent of the idea that different natural languages are alternative conventional systems for expressing a genetically-fixed system of meanings is surely Steven Pinker. Yet Pinker has written (1998) “I agree that U[niversal] G[rammar] has been poorly defended and documented in the linguistics literature”. Pinker was saying here that insufficient evidence has been brought forward to support the Universal Grammar hypothesis; the linguists I have cited have been producing abundant evidence against the hypothesis. Although Universal Grammar might have lent plausibility to the grammaticality/ungrammaticality distinction, if it had itself been plausible, at the beginning of the 21st century it appears to be no more than an exploded dogma.
(I discuss the unlikelihood that any aspects of natural-language structure are innate in Sampson (2005a: passim).)
Realistic grammatical description
Finally: if natural languages do not comprise well-defined sets of grammatical sentences, what then is left for grammatical description to aim at? For half a century, many linguists have found Chomsky’s formulation of that task, namely as separating the grammatical from the ungrammatical sequences of the language, to be a compelling one. What is there to replace it with?
Consider again the metaphor of a language as an unfenced prairie in which people have made tracks frequented to different extents and hence of different sizes. Describing the grammar of a language, I suggest, is like describing the network of tracks down to some size threshold below which fainter paths are ignored. Someone who buys a road atlas of Great Britain does not complain and ask for his money back if he sees a man walking his dog along a field path which is not registered in the atlas. The analogy is not perfect, because in Britain there are sharp cutoffs, physically between routes which are metalled and those which are not, and legally between routes which are publicly available for vehicular use and those which are private, or publicly available as footpaths or bridleways only. A modern road atlas will probably attempt to register all and only the routes meeting one of these clearcut criteria – very likely the legal one. But there could be road atlases in cultures lacking the invention of tarmacadam, and where laws of access are vaguer than in modern Britain; the atlas compilers would have to make some kind of decision about how far to go, in marking routes on their maps, down the scale from crowded, well-beaten highways to occasional footpaths, but whatever cutoff point they chose would be arbitrary.
In a literate society there is even a kind of linguistic analogue for the legal cutoff between public highways and other tracks. Writing, particularly published writing, is held to public standards of grammatical normality by institutions such as writing-skills education, copy-editing of manuscripts, and so forth, which have the effect of discouraging many of the quirkier, one-off turns of phrase that people who speak in informal contexts are free to deploy. If instead of the SUSANNE treebank I had based the analysis of Figure 1 on the CHRISTINE treebank of spontaneous spoken English, I expect I might have encountered a richer variety of Dunster constructions.[7] (I did not use CHRISTINE, because speech data would have raised complex issues relating to dialect differences, difficulties of interpreting utterances out of context, and many others which would inevitably have taken this paper over and diverted attention from its central theme.) But although copy-editors, for instance, encourage writers to keep to the wider grammatical highways rather than obscure footpaths, they do not really possess a tacit or explicit language model that is sufficiently well-defined to allow one to specify “all and only” the sentence-structures which count as editorially-acceptable English. (And even if they did, what linguists are primarily interested in is language as an aspect of human beings’ natural behaviour, including spontaneous speaking, rather than a well-behaved subset of ordinary language that has been promulgated for “official” purposes.)
Traditional grammar description, it seems to me, was carried out in a spirit similar to road-atlas compilation in a pre-modern society as I envisaged it above. Grammarians such as Jespersen or Zandvoort, or authors of grammars for schoolchildren’s use, who wrote before the middle of the 20th century aimed to describe the more usual ways in which utterances are constructed in the language under description, but without any stated or tacit rider that “these and only these constructions are grammatical” in the language. The cutoff between constructions well-established enough to describe, and turns of phrase so unusual that the grammar is silent about them, would have been determined by the resources available to the grammarian – his own time, the size of book acceptable to his publisher, or the like – rather than by a concept of ungrammaticality.
This is still, in my view, the right way to construe the task of grammatical description. (Newmeyer might prefer to call it “usage description”; but if usage is all there is, then I take it that the work of describing it will be called grammar, as it was before Syntactic Structures.) Computerized corpus techniques help us find out facts about usage today which grammarians of fifty years and more ago might not have been able to ascertain because it would have taken too much effort, so in some respects we can improve on their grammatical descriptions; but the essential point, that the cutoff in delicacy of grammatical description is an arbitrary one, is as true now as it was then.
This suggests consequences which may be uncongenial to many linguists. The generative concept of an ideal grammar which succeeds in defining “all and only” the sequences constituting an individual’s language is easily interpreted as a system which is psychologically real for that individual; by coinciding perfectly with the speaker’s usage, the structure of the grammar might succeed in reflecting aspects of the structure or functioning of the speaker’s mind. It does not seem tempting to suppose that a grammar which identifies the constructions used most frequently (by an individual, or by a speech community) down to some arbitrary cutoff could tell us much about speaker psychology.
But then, over the half-century during which the generative conception of grammar has been influential, it does not appear that the possibility in principle that grammars could tell us about minds has led to many specific discoveries about mental functioning or mental structure. And indeed it is notorious that the ideal of a grammar which fully succeeds in correctly distinguishing grammatical from ungrammatical sequences has never been attained for even one speaker. So perhaps relinquishing the hypothetical possibility of defining “psychologically real” grammars is not really giving much up.
Whether that is a large renunciation or not, I believe that the conception of grammatical description outlined here is the most that scientific linguistics can realistically hope to achieve.
References
Aronoff, M. 1976. Word Formation in Generative Grammar. MIT Press.
Babarczy, Anna, J.A. Carroll, and G.R. Sampson. 2006. “Definitional, personal, and mechanical constraints on part of speech annotation performance”. Journal of Natural Language Engineering 12.77–90.
Bauer, L. 1990. “Be-heading the word”. Journal of Linguistics 26.1–31.
Briscoe, E.J. 1990. “English noun phrases are regular: a reply to Professor Sampson”. In J. Aarts and W. Meijs, eds., Theory and Practice in Corpus Linguistics, Rodopi (Amsterdam), pp. 45–60.
Carlson, G., and T. Roeper. 1980. “Morphology and subcategorization: case and the unmarked complex verb”. In T. Hoekstra et al., eds., Lexical Grammar, Foris (Dordrecht), pp. 123–64.
Carnie, Andrew. 2002. Syntax: A generative introduction. Blackwell (Oxford).
Chipere, N. 2003. Understanding Complex Sentences. Palgrave Macmillan.
Chomsky, A.N. 1975. Reflections on Language. Page references to 1976 Temple Smith edition, London.
Cowart, W. 1997. Experimental Syntax. SAGE.
Culy, C. 1998. “Statistical distribution and the grammatical/ungrammatical distinction”. Grammars 1.1–13.
Deutscher, G. 2000. Syntactic Change in Akkadian: the evolution of sentential complementation. Oxford University Press.
Everett, D.L. 2005. “Cultural constraints on grammar and cognition in Pirahã”. Current Anthropology 46.621–46.
Gil, D. 2001. “Escaping Eurocentrism: fieldwork as a process of unlearning”. In P. Newman and M. Ratliff, eds., Linguistic Fieldwork, Cambridge University Press, pp. 102–32.
Householder, F.W. 1973. “On arguments from asterisks”. Foundations of Language 10.365–76.
Jackendoff, R.S. 1993. Patterns in the Mind. Harvester Wheatsheaf.
Labov, W. 1970. “The study of language in its social context”. Studium Generale 23.30–87. Page reference to reprint in Labov, Sociolinguistic Patterns, Blackwell (Oxford), 1978.
Labov, W. 1975. What is a Linguistic Fact? Peter de Ridder (Lisse). Also published under the title “Empirical foundations of linguistic theory” in R. Austerlitz, ed., The Scope of American Linguistics, Peter de Ridder (Lisse), 1975, pp. 159–96.
Langendoen, D.T. 1969. The Study of Syntax. Holt, Rinehart & Winston.
Lin, Dekang. 2003. “Dependency-based evaluation of Minipar”. In Anne Abeillé, ed., Treebanks, Kluwer, Dordrecht, pp. 317–29.
Mortimer, John. 1992. Dunster. Viking. Page reference to 1993 Penguin edition.
Newmeyer, F.J. 2003. “Grammar is grammar and usage is usage”. Language 79.682–707.
Nunnally, T.E. 2002. Review of Moon, Fixed Expressions and Idioms in English. Language 78.172–7.
Piattelli-Palmarini, M., ed. 1980. Language and Learning. Routledge & Kegan Paul.
Pinker, S. 1998. Posting 9.1209 on the Linguist List, 1 Sep 1998.
Pullum, G.K., and Barbara C. Scholz. 2002. “Empirical asssessment of stimulus poverty arguments”. The Linguistic Review 19.9–50.
Quine, W. van O. 1951. “Two dogmas of empiricism”. Philosophical Review 60.20–43; reprinted as chapter 2 of Quine, From a Logical Point of View, 2nd ed., Harper & Row (New York), 1963.
Roeper, T., and M. Siegel. 1978. “A lexical transformation for verbal compounds”. Linguistic Inquiry 9.199–260.
Russell, B. 1957. “Mr. Strawson on referring”. Mind n.s. 66.385–9. Page reference to reprint in A.P. Martinich, ed., The Philosophy of Language, 4th ed., Oxford University Press, 2001, pp. 243–6.
Sampson, G.R. 1987. “Evidence against the ‘grammatical’ / ‘ungrammatical’ distinction”. In W. Meijs, ed., Corpus Linguistics and Beyond, Rodopi, Amsterdam, pp. 219–26; a version reprinted in Sampson 2001, chapter 10.
Sampson, G.R. 1995. English for the Computer. Clarendon Press (Oxford).
Sampson, G.R. 2001. Empirical Linguistics. Continuum.
Sampson, G.R. 2002. “Exploring the richness of the stimulus”. The Linguistic Review 19.73–104.
Sampson, G.R. 2005a. The “Language Instinct” Debate. Continuum.
Sampson, G.R. 2005b. “Quantifying the shift towards empirical methods”. International Journal of Corpus Linguistics 10.15–36.
Sampson, G.R., and Anna Babarczy. Forthcoming. “Definitional and human constraints on structural annotation of English”.
Sapir, E. 1921. Language. Page reference to Rupert Hart-Davis edition, 1963.
Taylor, Lolita, et al. 1989. “The syntactic regularity of English noun phrases”. Proceedings of the Fourth Conference of the European Chapter of the Association for Computational Linguistics, UMIST (Manchester), April 1989, pp. 256–63.
White, M.G. 1950. “The analytic and the synthetic: an untenable dualism”. In S. Hook, ed., John Dewey: Philosopher of Science and Freedom, Dial Press (New York), pp. 316–30; reprinted as chapter 14 of L. Linsky, ed., Semantics and the Philosophy of Language, University of Illinois Press, 1952.
Wittgenstein, L. 1953. Philosophical Investigations. Blackwell (Oxford).
At this point, the journal special issue will
include responses to the above from:
•
Antti Arppe and Juhani Järvikivi
•
Jennifer Foster
•
Thomas Hoffmann
•
W. Detmar Meurers
•
Geoffrey K. Pullum
•
Anatol Stefanowitsch
to which the following is my reply:
Reply
My thesis restated
The responses to my target article are thoughtful and interesting. It is a matter of regret to me, though, that some of them say little about the issue which I aimed to raise.
I urged that a key tenet of generative linguistics may be a delusion. That doctrine is that the class of all possible sequences over the vocabulary of a language can be divided into two subsets, a set of grammatical sequences and a set of ungrammatical sequences, and that we can in principle establish where the dividing-line falls. I suggested that it might be more realistic to think in terms of a three-way classification, between (1) sequences for which speakers have already found uses, (2) sequences for which uses have not yet been found but which will one day find a use, and (3) sequences that will never have a use; and I suggested that the boundary between (1) and (2) + (3) might in principle be knowable but is of no intellectual interest, while that between (1) + (2) and (3) is not in principle knowable even approximately. (Necessarily, in this reply I am abbreviating difficult ideas – I find them difficult – which I expounded at greater length in the original article; I hope that subsequent critics will not seize on brief and perhaps oversimplified wording in the reply in order to pick holes to which the fuller exposition in the target article is not vulnerable.)
Re-reading my target article some time after I wrote it, I continue to feel that this view, if not certainly correct, is at least plausible enough to be worth serious discussion. Several respondents, though, focus the bulk of their attention on subsidiary points rather than on the issue which for me was central.
There is a degree of overlap, as one would expect, among the various points made by respondents. I hope that they will forgive me if, to keep the length of this reply in bounds, I do not try to list each passage in the responses which bears on a given point. I shall quote representative passages in my discussion, but if that happens to lead to my quoting from some respondents more than from others this should not be taken to imply any undervaluation of the less-quoted responses.
Direct responses
The responses which engage most closely with my central thesis are those by Anatol Stefanowitsch, and Geoffrey Pullum.
Stefanowitsch agrees with my idea and offers a case-study in its support; there is little I can say in reply other than to commend his interesting paper. Rather than a language being defined by grammatical rules, Stefanowitsch argues, it is channelled into customary patterns by conventions, “but where a strong enough communicative need arises … speakers are happy to ignore those conventions and use their language in a way that suits their purposes.” Just so.
Pullum, on the other hand, sets out to refute my thesis, with his customary verve. Pullum’s attack is more energetic than well-focused, however. His opening gambit, which he apparently sees as a telling blow, consists of writing a long sentence backwards and suggesting that I imply there is nothing odd about it. As an argument, this is on a par with someone who encounters the idea that the world is round rather than flat and responds “So how come the Australians don’t fall off? – ha, bet you never thought of that one!”
Pullum goes on to argue that linguists should see their objects of study as systems of norms, to be identified by methods similar to those that certain philosophers see as appropriate for describing systems of aesthetic or ethical norms. Having begun by condemning my thesis as “extraordinary” and one that will “give corpus linguistics a bad name”, Pullum proposes a view of grammatical research that departs far further than mine from the consensus. I was at least assuming that grammatical description consists of statements that are correct or incorrect: but correctness is not a concept applicable to the domains of ethics or aesthetics. (As it is often put in the case of ethics, “you cannot derive an ought from an is”.)
Then, a page or two later, Pullum urges that grammarians need to become “a lot more conversant with ways of mathematicizing their subject matter”, blithely ignoring the conflict between that recommendation and the appeal to treat linguistics as a discipline concerned with norms. The gulf between formal mathematical discourse, and discourse about norms, is about as wide as any chasm in the map of learning. I suppose one might say that utilitarian ethics is about quantities, but not quantities which are subjects of subtle mathematical calculation. Have any philosophers of aesthetics or ethics ever attempted to mathematicize their domain? Perhaps one has, and Pullum will triumphantly (and correctly) accuse me of not having read that one. But at least it seems clear that Pullum is opening up a range of methodological ideas more diverse than anything I suggested, and is adumbrating them too briefly for me to feel obliged to take them on board. Faced with these scattered potshots, I prefer to continue plodding forward on my original line of march rather than break formation in order to try to deal with them. (I take up Pullum’s specific point about research by Christopher Culy later in this reply.)
Pullum’s closing sentence asserts that the doctrine I was calling into question is “millennia old”. As said in the third paragraph of my target article, I do not believe that is true. So far as I am aware, the idea of the class of all sequences of words being divisible into grammatical and ungrammatical subsets was original with Noam Chomsky, in the Syntactic Structures passage I quoted there.[8] Pullum says that the age-old standard view of a grammar is that it tells us what is well-formed and “by implication” what is not, but I do not believe that grammarians before Chomsky saw that “implication” as valid.[9] I do not see the implication as valid, either. That is precisely the point of my article – so perhaps Pullum disagrees with me not so much because he has considered my point of view and rejected it, but rather because he has not fully understood it. If Pullum is right to suggest that Chomsky’s formalization of the concept “grammar” merely restated a long-held idea, I should be very interested to see corroborative quotations predating Chomsky.
This communication failure possibly explains why other respondents have focused chiefly on subsidiary issues. Chomsky’s Syntactic Structures has been so successful in defining how subsequent linguists envisage their subject that a contrary position has become not just unorthodox but literally incomprehensible. In his enthusiasm to assert his own views, Pullum forges ahead without even realizing that he is missing my point. Others, more circumspectly, pick out aspects of my discussion which do say something to them and leave aside aspects which do not.
That is not to say that the other respondents entirely overlook my central thesis. Meurers, for example, tries to accommodate my doubts about grammaticality through an analogy with architecture: the laws of statics impose limits on what structures can be built, even though some impossible structures might have been useful if they were buildable, and even though there is a great deal to say about the architectural virtues or failings of the diverse structures which are permitted by physical law. Rather than being like a set of paths in grassland, Meurers suggests that a language is like a set of paths in mountainous terrain, where some routes are quite impossible. These are vivid analogies to illustrate the idea that natural languages might rule some (perhaps many) strings out as altogether ungrammatical, even though the strings which are grammatical are by no means all on a par in terms of naturalness, usefulness, etc. The analogies are clear, but I am arguing that the picture of language which they suggest is wrong: natural languages are like paths in grassland rather than in mountains. I do not find that Meurers gives real reasons for preferring his picture.
When I speak, it does not feel to me as if there are rigid laws preventing me saying some things. (Surely every teacher of generative linguistics has had the experience of explaining to an outsider that grammars show why one cannot say things like Furiously sleep ideas green colourless, only to encounter the response “What do you mean? Furiously sleep ideas green colourless – there, I’ve just said it.” I doubt whether many architects encounter comparable scepticism about the role of guidelines limiting the loads which particular types of wall can bear.) So what is the actual evidence that these rigid constraints exist?
The nature of scientific method
More interesting than my central thesis, to several respondents, is evidently the issue of whether generative linguistics as it stands is – and, if not, whether it should be – an empirical science. I agree that these are interesting questions, so let me reply to this aspect of the responses even though this was not the topic on which I was hoping to stimulate discussion.
An initial point is that some respondents have evidently misunderstood what I mean by calling for linguistics to adopt empirical scientific method. More than one respondent implies that I recognize nothing but corpus work as empirical. I am not sure what has led to that misunderstanding. (Perhaps it stems partly from the title of this journal, but I cannot take responsibility for that.) I work with corpora myself, and because of the sparse-data problem which besets grammatical research I do believe that large machine-searchable corpora are specially valuable resources in this field, but to me it would be absurd to suggest that corpus linguistics is the only possible kind of empirical linguistics (and I doubt whether those who chose the journal title had such an idea in mind).
I will quote just two, very different counterexamples to that absurdity (from a legion that I could have chosen). When William Labov investigated the social stratification of English in New York department stores by asking assistants questions designed to elicit spontaneous utterances of the phrase “fourth floor” (Labov 1966: 70–2), what he was doing was nothing like corpus linguistics, but was certainly empirical science. Again, Carson Schütze (1996) – cited approvingly by several respondents – refers to a technique in which electroencephalograph readings are taken while subjects are presented with verbal stimuli: also entirely empirical and nothing to do with corpora. In my recent attempt to quantify how far linguistics has shifted towards empirical methods, I was careful to say explicitly that empirical data are not necessarily corpus data (Sampson 2005b: 26).
What makes a theory empirical is that it is answerable to interpersonally-observable data. An utterance of “fourth floor” by a department-store assistant is an empirical datum; a speaker’s feeling that a given word-string is good or bad (acceptable or unacceptable, grammatical or ungrammatical, …) is not an empirical datum, because another person cannot check that same feeling (though the other person may have a feeling of his own about the string, which may coincide or otherwise). Meurers complains that “Sampson unfortunately does not list what he considers to fall under interpersonally observable evidence”. I am not sure whether Meurers genuinely does not understand the phrase, which is no more than my attempt to express what has been a standard principle during the three centuries since the Enlightenment,[10] or whether he feels that someone who embraces empirical techniques is obliged to enumerate a fixed list of all and only the specific types of evidence that are deemed to “count” within a particular scientific subject. No recognized exponent of scientific method would agree with the latter. It is frequently pointed out that the scientific method is not an algorithm which can be applied mechanically. A scientist needs to be imaginative and resourceful in thinking of theories and ways of testing them; the requirement is only that the theories can, somehow, be tested in ways that do not depend on access to private feelings. (Doubtless these few words are not a watertight definition of empirical scientific method, but within an article of finite length one must surely be allowed to take as read some things which are as basic to modern civilization as this is.)
Another misunderstanding that seems to be shared by some of the respondents is that, if one advocates empirical scientific method, then (they suppose) one is obliged to quote evidence for each and every statement of fact one makes. Pullum describes my reference to the variation in how people list the days of the week as a “claimed fact (from undocumented survey work)”. I see no way of interpreting this other than as a snide insinuation that I may have invented the point, because if it were true I ought to have quoted hard evidence. But, even where data are crucial to one’s argument, empirical scientific method does not – and could not – impose such a requirement on practitioners. If one’s data are interpersonally-observable facts, it will always be possible for a sceptic to call some of them into question, in which case they must be shored up by reference to data which are “more basic”, and the potential regress has no end. Rather than continuing to spell out at length standard methodological principles which should be common ground, I refer readers to my discussion (Sampson 2005b: 23–4) of Karl Popper’s metaphor of the structure built on piles in a swamp.
(In this particular case, Pullum’s insinuation is specially silly, because my argument did not depend on the truth of the days-of-the-week point; that was offered only as an illustrative analogy to help readers grasp what I was trying to say about grammar. It surprises me that Pullum doubts this statement about speaker behaviour – has he really never heard someone listing the days differently from the way he does it himself, and why does he suppose publishers of pocket diaries print them in alternative, Sunday-to-Saturday and Monday-to-Sunday versions? – but even if he thought I was just wrong about that point, this would not damage my thesis.)
Conceptual objections to my thesis
Some respondents suggest that possession by speakers of a “mental grammar” generating a grammatical/ungrammatical distinction is something like a conceptual or scientific necessity. Arguing that my road-atlas picture of descriptive linguistics is inadequate, Hoffmann writes “science does not stop at simply documenting data, it aims at explaining them … the source of any variability must be the speakers’ mental grammar”.
The idea that linguistics must not only “describe” but “explain” is another of the axioms which Chomsky has persuaded the discipline to accept as self-evident truths (the loci classici here being Chomsky 1964: 28–30 and 1965: 24–7). But this distinction seems to me much less clear than linguists commonly take it to be – I believe the axiom functions at least in part as a device for inducing linguists to agree that only the generative style of linguistics meets the requirements of a respectable scholarly undertaking, without going to the trouble of arguing the point; and if the suggestion is that the axiom holds for linguistics because it holds for all intellectual disciplines, that is surely false. There is a well known contrast between subjects like physics, where individual events repeatedly instantiate fixed predictive laws, and subjects like history, which describe unique sequences of events not predictable by general laws.[11] This contrast relates to the distinction labelled in English “science” v. “arts” or “humanities”, though that usage is tendentious since the etymology of “science” seems to imply that arts subjects are not concerned with knowledge at all; German offers more neutral terminology in Naturwissenschaften v. Geisteswissenschaften. But in fact not all “natural sciences” clearly resemble physics more than history. Evolutionary biology is arguably more like history: it deals with unrepeated processes of emergence of unpredictable innovations over time. Philosophers of science recognize it as a large question how, if at all, standard concepts of natural science, developed mainly by reference to physics, apply to biology (Ruse 1973). It is not obvious to me that the study of human language should be expected to yield the kind of predictive laws characteristic of physics, whether the laws relate to individual languages or to human language in general. (This is a point made by Arppe and Järvikivi, though they do not draw my conclusion that we shall not discover grammars which predict that some strings of words are unusable.)
Incidentally, while my thesis does imply that the ambitions of linguistics should be scaled down from what generative linguistics suggests, I do not think of that as a “pessimistic” view, as Arppe and Järvikivi repeatedly describe it. We are all, surely, human beings first and scientists a distant second. As a human being I do not relish the idea that my and my fellows’ behaviour is limited by rigid laws akin to those which predict the behaviour of inanimate objects.
As for the suggestion that speakers “must” have a “mental grammar” in their heads: this seems a strangely inflexible view of how human language could conceivably work. Suppose, for instance, that Rens Bod’s “DOP” (data-oriented parsing) theory were broadly on the right lines (see e.g. Bod and Scha 1996, Bod, Scha, and Sima’an 2003). It is not my concern here whether DOP will ultimately prove to be correct or incorrect (I would not presume to predict), but it surely cannot be rejected out of hand as conceptually untenable? If not, that is one alternative to generative grammar as a model of human language behaviour, which seems to meet all the requirements for consideration as a serious scientific theory, but which has nothing within it that one could identify as a “mental grammar”.
Can intuition-based linguistics be empirical?
Moving on from the question of what we mean by empirical scientific method, several respondents argue that generative linguistics in practice is more empirical than I suggest. They list a number of recent books and articles which are claimed to resolve the tension between empirical method and use of speaker intuitions as data, pointing out that my target article cites very little of this literature.
The last point is certainly true. Many of the writings listed were not yet published when I wrote my article, and some of them have not been published now. (The work for my target article, including the data analysis which yielded Figure 1, was carried out in response to the editors’ invitation over a period of about two months in 2005, but, having submitted my manuscript in October of that year, I waited until December 2006 for the responses to be assembled; the discipline of linguistics naturally did not stand still during all that time.) However, I am not sure that the tenor of my article would have changed much if these writings had been available to me when I wrote it. Just listing publications does not tell us much more than that some linguists are aware that there is an issue here – it would be truly extraordinary if that were not so. It does not in itself show that the problem I discussed has been solved.
Consider for instance the 1996 book by Carson Schütze already mentioned, which is cited by Hoffmann, by Arppe and Järvikivi, and by Jennifer Foster. Schütze’s book is an interesting one, which takes seriously questions about the evidential basis of generative linguistics that were scarcely considered earlier. It is a step in the right direction – but only a step. It certainly does not amount to a demonstration that generative linguistics as standardly practised is an empirical science (which it is not).
At one point (pp. 48–52), Schütze discusses the psychologist Wilhelm Wundt’s use of introspective techniques,[12] which he sees as methodologically unacceptable, but he then argues that generative linguists’ use of speakers’ “intuitions” is not a form of “introspection”. I have read this passage several times, when the book appeared and again now, but I cannot understand it. “Intuition” (as that word is used in generative linguistics) and “introspection” seem to be just two names for the same thing, and that thing is a phenomenon which is essentially private rather than intersubjective.
Of course, people’s reports of their linguistic intuitions or introspections are themselves intersubjectively observable data, and it would be possible to construct empirical descriptions of those reports; Schütze (p. 4) notes that many writers have suggested that that is in effect what generative linguists do, though they claim to be doing something else. The writers Schütze refers to are correct, in my view.
A defender of the use of intuitive data might say: suppose we find some set of techniques for gathering and systematizing speakers’ grammaticality judgements that is shown experimentally to make predictions about usage which coincide perfectly, within the limits of experiment, with what speakers are observed to utter and not to utter in spontaneous speech – would an empirical scientist still be obliged to avoid drawing on the intuitive data in constructing language descriptions? No, in those hypothetical circumstances it would clearly be sensible for the empirical scientist to draw on intuitions as a convenient short-cut towards formulating adequate language descriptions.
But notice, in the first place, that the experimental findings would have to overcome quite a high hurdle before this became appropriate. The first objection that sceptics tend to make to data about speaker intuitions is that they seem chaotic, or even contradictory (in so far as it is meaningful to think of one person’s private feeling as “contradicting” someone else’s private feeling). So it might seem that the problem with intuitive data would be solved if we could find techniques for eliciting consistent, systematic intuitions; and defenders of intuition-based linguistics sometimes claim that such techniques are available. (See for instance Arppe and Järvikivi’s remarks in the passage where they cite “Keller 2000, Featherston 2005, Kempen and Harbusch 2005 [etc.]”.) But the fact that sophisticated techniques may succeed in identifying systematic patterns of intuition underlying apparent chaos is not in itself an adequate reason for treating the systematic patterns as a reliable guide to the true structure of the speakers’ language. Factors which cause a person’s linguistic intuitions to fail to reflect his language behaviour may themselves be systematic – they often are. For instance, many people’s intuitions about “their language” are heavily though unconsciously influenced by the properties actually possessed by another dialect, or even a quite separate language, which happens to have higher prestige in their society. At a period when the study of Latin was a core element of British education, many English speakers sincerely believed that their use of English had various properties which no form of English actually possesses, but Latin does possess.
So, before it became reasonable for empirical scientists to use intuitive linguistic data as short cuts, they would need to establish that these data could not merely be systematized but that this could be done in a way that reflected the speakers’ own usage rather than any interfering factors – this would be difficult to achieve. Extraneous factors may influence different individuals in the same way. Hoffmann misses this point, writing “if it can be shown that judgments elicited via carefully constructed experiments are in fact intra- and inter-subject consistent … then it is much more plausible to assume that this is due to speakers sharing aspects of their mental grammars” – and Schütze came close to embracing the same fallacy when he wrote (op. cit.: 77) “empirical facts are useful (and interesting) if they are systematic, because they must tell us something about the minds of the subjects who produce them.”
Moreover, even if the hurdle could be surmounted, the empirical linguist would need to remain alert to the possibility that the experimentally-established match between systematically-elicited intuitions and observed usage might break down in circumstances that the original experiments did not control for (one can never control for everything). Perhaps the intuitions can be shown to coincide with real usage across the range of normal circumstances in university research, but it might later turn out, say, that in some commercial environment, where speakers are routinely subject to pressures not commonly found in academic settings, their reported intuitions would turn out to diverge from their actual usage – if so, the empirical scientist must forget the intuitions and base his description on observed usage. In the long run, it might be simpler to use observable data from the start.
My target article said that if we have a language-description based on empirical data, then an intuition-based description would be redundant; Hoffmann objects that when two people witness a crime, the police do not take just one of their statements. That is a false analogy: the two witnesses are logically equivalent in status. A better analogy is that, if we have used a ruler to measure the precise length of a line, we will not be interested in asking a person to estimate the length by eye.
Bear in mind that these are not just fine-drawn philosophical considerations which the practical working generative linguist can afford to ignore. My target article gave specific, concrete examples of erroneous theoretical conclusions which have been held widely, and which depend for their plausibility on the assumption that speakers’, or linguists’, intuitions are veridical. They included one issue which is crucial to what is claimed as the leading “discovery” of generative linguistics (the idea that language structure is largely innate in our species).
Is generative linguistics empirical?
I have argued, contrary to some of the respondents, that it is not clear that a version of linguistics which makes heavy use of intuitive data could be an empirical science. But the further point is that, whether or not writers such as Schütze have succeeded in showing that such a version of linguistics could in principle be empirical, generative linguistics in practice certainly is not empirical. Arppe and Järvikivi say that it is a “mischaracterization” to describe generative linguistics as “inherently an intuition-based scientific enterprise”; but the description is accurate. Of course, in a worldwide activity as loosely organized as academic research, one will always be able to find isolated exceptions to any generalization – and one cannot specify a rigid partitioning of a subject into separate schools, enabling one to describe A as a “true generative linguist” while B, who writes in a more empirical style, is, say, a “cognitive linguist rather than a generative linguist”. Such categories are always blurry at the edges. But the generative paradigm which has dominated linguistics throughout my working life has been overwhelmingly intuition-based.
Notice that the very earliest of the publications which Hoffmann, and Arppe and Järvikivi, list as identifying ways in which empirical method might be reconciled with intuitive data are Schütze (1996) and Ellen Bard et al. (1996). By 1996, generative linguistics had been the dominant paradigm in the subject for a full generation. (When Syntactic Structures appeared, I believe the average linguist saw it as a possibly interesting but idiosyncratic approach to the subject, but by 1965 it seems fair to say that Aspects of the Theory of Syntax was accepted as the manifesto of the new mainstream way of doing linguistics.) During those three decades, very few generative linguists cared twopence about empiricist objections to the use of intuitive data. Most corpus linguists have heard about R.B. Lees’s scornful reaction in the early 1960s to the news that W. Nelson Francis had obtained funding to create the first electronic corpus of English: “That is a complete waste of your time and the government’s money. You are a native speaker of English; in ten minutes you can produce more illustrations of any point in English grammar than you will find in many millions of words of random text” (quoted in Biber and Finegan 1991: 204). Francis’s Brown Corpus was available from 1964 on, but for decades little use was made of it.[13] My target article mentioned the very extensive range of types of linguistic fact which Terence Langendoen, in his elementary 1969 textbook, claimed that any speaker knows and can express about his language; Langendoen was LSA President in 1998. Lees is no longer alive, and I do not know whether Langendoen still holds the views he held in 1969, but comparable attitudes continue to be openly and frequently expressed. If linguistics is claimed to be a cumulative subject, where new findings are built upon results established earlier, then its lower storeys are so rotten that it would be no use to move towards more respectable techniques in future work.
In any case, is there any realistic likelihood that generative linguists would decide in large numbers to adopt the challenging, experimental-psychology-inspired protocols for systematizing data elicitation that writers such as Schütze recommend? I do not believe it. Kepser and Reis (2005: 2) claim that Schütze’s book was an “important turning point”, but although the book won respect, and may well have helped to encourage the flourishing of corpus-based research which began at about that time, I am not sure that it led to much change in the way that linguists used intuitive data. Wasow and Arnold (2005), also cited approvingly by Arppe and Järvikivi, do not think it did: “the findings of the experimentalists in linguistics very rarely play a role in the work of generative grammarians. Rather, theory development tends to follow its own course, tested only by the unreliable and sometimes malleable intuitions of the theorists themselves.” Arppe and Järvikivi cite the contents of the Kepser and Reis book as evidence that the tide is turning now – but one conference proceedings, however sensible the participants, seems a thin justification for discerning a secular change in the complexion of a discipline.
For mainstream generative linguists, the undemanding nature of their research style is part of its attraction (cf. Postal 1988). You make up some research findings out of your head, publish them in a forum controlled by similarly non-empirical linguists, and after a few years you have got yourself a career. Noam Chomsky has rarely subjected himself even to the discipline of publishing in refereed journals (Pullum 1997) (and he neglects other norms of academic behaviour, such as acknowledging precedence of ideas: Pullum 1996); so how could we expect his followers to accept far more burdensome constraints on their programmes of research? They won’t. Linguistics will not move forward healthily until the generative approach is bypassed as the pseudoscience it is, with its remaining practitioners retiring from academic life and new recruits to the discipline ignoring its ethos, assumptions, and alleged results.
The sum of human knowledge will not thereby be reduced. When people set out to theorize a domain which in reality is not governed by predictive laws, we can expect to see theory after theory put forward without concrete progress; and that describes the history of generative linguistics. It is not just external observers who comment on “the lack of any real forward movement in [syntactic] theory: alternative analyses seem to succeed each other more due to fashion than due to falsification” (Featherston 2005: 187). The creator of generative linguistics himself recently suggested that in half a century it has produced no results at all (cf. the excerpts from a Chomsky interview in Postal 2004: 342 n. 11). Others such as Steven Pinker (1994) believe that it has shown that human knowledge of language is largely innate (and Chomsky frequently argued this in the past), but the arguments purporting to establish that are laughably flawed (Sampson 2005a). In abandoning generative linguistics, we lose nothing; trying to mend generative linguistics at this late date is a hopeless undertaking. On that, Pullum and I agree.
It may be that the contents of Kepser and Reis (2005), and other recent publications cited by the respondents, will be seen in twenty or thirty years’ time to have been harbingers of a successful movement which is destined to create a new, genuinely empirical linguistics. I hope that proves to be so. If it does, I predict that the new discipline will be found to owe little to the kind of linguistics which has enjoyed most prestige since the 1960s.
No virtue in extremism
Some respondents feel that my paper is not just misguided but actually self-contradictory in various ways. In particular, referring to my concession that things like violations of gender or person agreement might be categorized as truly ungrammatical, Pullum comments “Conveniently for critics … his paper contains a rejection of its own thesis”.
Certainly the point is a softening of my thesis, relative to the strongest form in which it might be held – Stefanowitsch sees it as an unnecessary softening. But even with the concession, there is plenty of the thesis left, and what is left clearly contradicts the assumptions of generative linguistics. Generativists assign asterisks to word-strings not just because of local agreement failures but also because the overall architecture of the strings is abnormal: they cannot be analysed into clauses and phrases which fit together in a standard way. Chomsky’s classic example *Furiously sleep ideas green colourless does not contain any concord error.
For Pullum to suggest that by offering the concession I am as good as surrendering (rejecting my own thesis) represents an approach to scholarship which I think of as characteristically American. It is not a desirable scholarly stance. The implication is that engaging in scholarly debate is a kind of warfare, where the aim is to blow the enemy out of the water. To admit any weakness is folly. But scholarship is not warfare. Of course all of us would like to see our particular pet ideas flourish within the intellectual ecosystem, but our higher allegiance is (or should be) to helping the truth to emerge. If we have an idea which we believe is essentially correct but which has areas of weakness, we ought to be the first to point out the weak points as well as the evidence in favour of the basic thesis. That is an ideal, and, being human, we will not always fully live up to it. But actually to satirize one’s intellectual opponent for being frank enough to make an open concession implies a depressing interpretation of the scholar’s mission.
Possibly related to the same point is Pullum’s suggestion that I am mistaken to accept that what he calls “Chomsky sentences” fail to occur in speech. (I say “possibly”, because I am not clear whether or not Pullum sees this as another weakening of my case, which I ought to have striven to avoid. To my mind, the finding that both sides in the controversy about Chomsky sentences – Chomsky and his followers, and Pullum and me – seemed to be wrong about the incidence of these constructions in real-life usage was even more significant than it would have been if Pullum and I had been fully correct.) Searching the British National Corpus, I found abundant Chomsky sentences in written language and none at all in spontaneous speech; admittedly my search technique was fairly crude. Pullum quotes cases he has heard which show that the constructions occur in speech also. I am not sure how robust his Wall Street Journal example is: while journalists on responsible newspapers are careful not to distort the sense of what is said orally by interviewees, it is normal for them to tidy up dysfluencies and the like, in ways that do not affect the content of what is said but might make a large difference from the point of view of a grammar theorist. However, we must clearly accept at least the first of the BBC World Service examples, as a verbatim transcription by Pullum. (The other World Service example may or may not be equally solid; I do not know why Pullum gives us only the opening words.)
The conclusion I drew from my BNC findings (Sampson 2005a: 79–88) was that written and spontaneous spoken English differ systematically in their toleration of Chomsky sentences (and that this fact underlay Chomsky’s erroneous belief that they never occur at all). I am not sure that this conclusion is incompatible with Pullum’s observation of between one and three spoken examples. I am not familiar with languages that are well known for having systematic grammatical differences between spoken and written registers (Czech and Arabic are sometimes cited as examples), but I surmise that characteristically-written constructions might occasionally show up in speech, though far less frequently than they do in writing. (Do French speakers not occasionally use the passé simple rather than the passé composé?) However, if the truth is that Chomsky sentences are reasonably frequent even in spontaneous spoken English, and my BNC search missed them because of some technical oversight, then my refutation of the argument for innate linguistic knowledge which Chomsky and his followers base on the non-occurrence of that construction would be all the stronger. I am more interested in discovering the truth, though, than in making my argument maximally strong.
Culy’s data
In another respect, Pullum believes that I have failed to surrender a position where I have been defeated, by Christopher Culy. According to Pullum, Culy (1998) demonstrated that the facts which are summarized graphically in my Figure 1 are irrelevant to the question whether there is a grammatical/ungrammatical distinction, so I ought not to continue to appeal to those data.
(Strictly, Culy was discussing not the present Figure 1, but a similar data set which I published in 1987 and reproduced on p. 170 of Sampson (2001). Pullum writes of Figure 1 above that “We have seen this graph before”, but that is not in fact true. It seemed to me that the 1987 data could reasonably be criticized as based on a small sample annotated to an unknown standard of reliability, so for the present target article I carried out a new analysis using a larger and more reliably-annotated sample. The specific numbers relevant to the two graphs, including their slopes, are different, but the smooth continuous log-linearity is common to both; that is the interesting finding for present purposes, and it may have been what led Pullum to take them for the same graph.)
Culy invented two artificial probabilistic grammars, one of which generates some but not all strings over its vocabulary (that is, it imposes a grammatical/ungrammatical distinction on the class of all possible strings), while the other generates all possible strings; and he showed that both assign frequencies to the strings they generate such that in either case the frequency distribution has a log-linear shape rather similar to my Figure 1. Culy argued that my data therefore do nothing to cast doubt on the grammatical/ungrammatical distinction. In fact the graph for Culy’s grammar with ungrammaticality, reproduced as Figure 10.2 (b) on p. 176 of Sampson (2001), is by no means as smoothly continuous and linear as either the 1987 data of mine to which he was responding, or the new data in my Figure 1 above (while the graph for the grammar that generates everything – loc. cit., Fig. 10.2 (a) – is much more similar to Figure 1). But, for the sake of argument, I am happy to accept that with further ingenuity Culy might be able to devise another artificial grammar which does embody a grammatical/ungrammatical distinction and matches the shape of my frequency-distributions better.
So far as I can see, Culy’s argument is a more fully-worked-out but not more compelling version of an objection already made repeatedly to my 1987 analysis by Edward Briscoe, which I answered at that time, and where Briscoe accepted the validity of my answer (for references to the various publications, see Sampson 2001: 173–4). The logic of Culy’s discussion is that we have a priori reasons to believe in a distinction between grammatical and ungrammatical strings in a language, but I have put forward numerical data which appear to refute that belief; Culy is showing how the distinction might be rescued from the implications of the numerical data. However, in reality we have no a priori reasons to believe in the distinction: it is an unmotivated postulate which was asserted in Syntactic Structures without argument. Were the type of statistical analysis exemplified by Figure 1 to display discontinuities suggesting a distinction between common grammatical sequences and sporadic performance deviations, then that might be a reason to postulate language-definitions in the form of grammars which assign the property of ungrammaticality to some strings. But when these graphs advance in a smooth, continuous, linear fashion towards areas of the frequency spectrum where it is impossible to test for grammaticality by systematic observation, it is hard to take seriously the idea that the data are governed by a finite set of rules whose interactions, and probabilities, just happen to mesh with one another in precisely the right ways to yield overall statistics containing no hint of discontinuity. The reasonable conclusion must rather be that a complex grammar generating a grammatical/ungrammatical distinction is an implausible, redundant postulate.
Sulking as an intellectual strategy
A final reaction to this collection of responses is: where are my real opponents?
Mainstream generative linguists should be deeply hostile to my central thesis. As Stefanowitsch puts it, it “rob[s] them of their explicandum”. And Stefanowitsch is graphic about the reactions he has encountered to the strong form of the thesis (“from incredulity to outright profanity, with occasional threats of physical violence” – I hope for Stefanowitsch’s sake that there is an element of exaggeration here!) Yet, although most of these respondents disagree with me to a limited extent, the only one of them who wholeheartedly rejects my point of view is Pullum – and Pullum is as dogged an opponent as I am of mainstream generative linguistics.
The measured tone of most of the dissent is doubtless partly due to the respondents’ natural courtesy. But I believe there is more to it: mainstream generative linguists do not like getting into debates with their opponents. The standard intellectual axiom is that there is a duty on scholars to engage in debate, because only the open clash of viewpoints leads to emergence of truth. But generative linguistics has aimed from the beginning to dominate the field hegemonically – already in 1963 the Voegelins complained about the “eclipsing stance” adopted by Chomsky and his early ally Roman Jakobson;[14] and the leaders of the movement calculate that continuing dominance is best achieved by denying their opponents the oxygen of publicity.
Various stories go the rounds about leaders of the generative school refusing, say, to appear on a conference platform if a particular non-generativist is also invited to speak. I have no right to give chapter and verse in the case of episodes for which I cannot vouch as having been personally involved, but the unwillingness of generativists to engage with my own critique of their position down the decades is obvious to third parties; Paul Postal has discussed it in detail (Postal 2005). In one remarkable manifestation of this avoidance, Steven Pinker has defended one of his theories against counter-examples I used to refute it, discussing my specific counter-examples (which were unusual and original with me) at length, yet never mentioning my name or the book in which I introduced them (Pinker 1999: 171–2; cf. Sampson 2005a: 128).
I believe that this syndrome may be part of the explanation for the surprising length of time that elapsed, as mentioned above, between my submitting my target article to this journal and being shown the responses. Although the editors very properly gave me no names, I gather that many people who might reasonably have been expected to be interested in my thesis either declined to write a response, or simply failed over a long period to produce one; and there was even one person who did send in a response but later withdrew it because (I paraphrase the editor’s explanation) he or she had come to see it as a bad career move to engage publicly with my ideas.
This is characteristic of the way mainstream generative linguists act towards those who disagree with them about fundamentals, and it helps to explain why the general public still appears to see Chomskyan linguistics and the idea of innate cognitive structure as an unchallenged consensus, despite the internal incoherence of this body of thought, and despite the number of scholars who are by now pointing out its flaws. For a school which has managed to attain a position of intellectual predominance to try to retain it by pretending that there are no challengers may work for a while with respect to the general public, who have little opportunity to detect the pretence. In the eyes of professionals who can monitor what is happening, though, it implies forfeiting the claim to be a serious intellectual discipline. In scholarly life, avoiding debate with opponents is close to an admission that one’s ideas are wrong or vacuous.
Linguistics is not the only discipline nowadays in which intellectual leaders fail to respect traditional scholarly norms. Even physics, commonly seen as the scientific discipline par excellence, is said (Woit 2006, Smolin 2006) to be suffering from a situation that sounds very like the one which the generativists have created in linguistics: “string theory” dominates fundamental physics with a doctrine that is vacuous, because unfalsifiable, yet is promoted so aggressively that holders of alternative views find career advance difficult. All academics nowadays are subject to pressures which were unknown in the profession (in my own country of Britain, at least) a generation ago, and these pressures may well make it difficult to maintain desirable norms of scholarly interaction. If so, then it is all the more important than those who understand how knowledge is most effectively advanced should speak out to preserve the ethos of scholarship.
I do not know whether the thesis of my target article will ultimately win general acceptance or not. However, I am very pleased to have had this opportunity of debating it publicly with a group of linguists including many sceptics. The truth is best served by such debates.
References
Bard, Ellen G., D. Robertson, and Antonella Sorace. 1996. “Magnitude estimation of linguistic acceptability”. Language 72.32–68.
Biber, D., and E. Finegan. 1991. “On the exploitation of computerized corpora in variation studies”. In Karin Aijmer and B. Altenberg, eds., English Corpus Linguistics, Longman, pp. 204–20.
Bod, L.W.M., and R.J.H. Scha. 1996. “Data-oriented language processing: an overview”. ILLC Research Report LP-96-13, Institute for Logic, Language and Computation, University of Amsterdam; reprinted in G.R. Sampson and Diana McCarthy, eds., Corpus Linguistics, Continuum, 2004, pp. 304–25.
Bod, L.W.M., R.J.H. Scha, and K. Sima’an, eds. 2003. Data-Oriented Parsing. CSLI Publications (Stanford, Calif.)
Chomsky, A.N. 1956. “Three models for the description of language”. IRE Transactions in Information Theory IT-2, pp. 113–24; reprinted in R.D. Luce, R.R. Bush, and E. Galanter, eds., Readings in Mathematical Psychology, Wiley, 1965, vol. 2, pp. 105–24.
Chomsky, A.N. 1957. Syntactic Structures. Mouton (the Hague).
Chomsky, A.N. 1964. Current Issues in Linguistic Theory. Mouton.
Chomsky, A.N. 1965. Aspects of the Theory of Syntax. MIT Press (Cambridge, Mass.)
Culy, C. 1998. “Statistical distribution and the grammatical/ungrammatical distinction”. Grammars 1.1–13.
Featherston, S. 2005. “The decathlon model of empirical syntax”. In Kepser and Reis 2005, pp. 187–208.
Kepser, S. and Marga Reis, eds. 2005. Linguistic Evidence. Mouton de Gruyter (Berlin).
Labov, W. 1966. The Social Stratification of English in New York City. Center for Applied Linguistics (Washington, D.C.)
Pinker, S. 1994. The Language Instinct. Penguin.
Pinker, S. 1999. Words and Rules. Weidenfeld & Nicolson.
Postal, P.M. 1988. “Advances in linguistic rhetoric”. Natural Language and Linguistic Theory 6.129–37; reprinted in Postal 2004, pp. 286–95.
Postal, P.M. 2004. Skeptical Linguistic Essays. Oxford University Press.
Postal, P.M. 2005. Foreword to Sampson 2005a.
Pullum, G.K. 1996. “Nostalgic views from Building 20”. Journal of Linguistics 32.137–47.
Pullum, G.K. 1997. “Does this man ever sleep?” Nature 386, 24 Apr 1997, p. 776.
Ruse, M. 1973. The Philosophy of Biology. Hutchinson.
Sampson, G.R. 2001. Empirical Linguistics. Continuum.
Sampson, G.R. 2005a. The “Language Instinct” Debate (revised edn). Continuum.
Sampson, G.R. 2005b. “Quantifying the shift towards empirical methods”. International Journal of Corpus Linguistics 10.15–36.
Schütze, C.T. 1996. The Empirical Base of Linguistics. University of Chicago Press.
Smolin, L. 2006. The Trouble With Physics. Houghton Mifflin (Boston, Mass.).
Voegelin, C.F. and Florence M. 1963. “On the history of structuralizing in 20th century America”. Anthropological Linguistics 5.12–37.
Wasow, T. and Jennifer Arnold. 2005. “Intuitions in linguistic argumentation”. Lingua 115.1481–96.
Woit, P. 2006. Not Even Wrong. Jonathan Cape.