The following online article has been derived mechanically from an MS produced on the way towards conventional print publication. Many details are likely to deviate from the print version; figures and footnotes may even be missing altogether, and where negotiation with journal editors has led to improvements in the published wording, these will not be reflected in this online version. Shortage of time makes it impossible for me to offer a more careful rendering. I hope that placing this imperfect version online may be useful to some readers, but they should note that the print version is definitive. I shall not let myself be held to the precise wording of an online version, where this differs from the print version. Published in International J. of Corpus Linguistics 10.15–36, 2005. |
Quantifying
the shift towards empirical methods*
Geoffrey Sampson
University of Sussex
Abstract
In recent decades there has been a trend towards greater use of empirical data, for instance corpus data, within linguistics. I analyse a sample of linguistics articles from the past half-century in order to establish a detailed profile for this trend. Based on consistent criteria for classifying papers as evidence-based, intuition-based, or neutral, the resulting profile shows that the trend (i) is real, but (ii) is strikingly weaker in general linguistics than in the special subfield of computational linguistics, and (iii) appears to have begun to go into reverse.
Keywords: empirical method; corpus linguistics; intuition
1. How empirical has linguistics become?
The idea for the research reported here arose when Diana McCarthy and I were compiling our corpus linguistics anthology (Sampson and McCarthy 2004). We looked for pieces that illustrate the various facets of that field, ranging from Charles Fries’s pioneering work of fifty years ago forward to 2002; and we decided that rather than grouping the anthology selections thematically, it would be more enlightening to mix the topics up and arrange the chapters of our book chronologically. We did not set a high premium on recency when selecting anthology items (often, a subject is illustrated more clearly by the publication that first inaugurated and defined it than by later articles which take for granted many things that new readers will not know). Nevertheless, I expected in advance that later decades would be represented by more items than earlier decades in the eventual collection. Once the selection process was complete, though, the pattern turned out to be more dramatic. The density of selections per decade grew only marginally from the 1960s through the 1970s to the 1980s, and then about 1990 there was something like an explosion, with a massively greater diversity of papers published over the last ten to twelve years than even a few years before.
This chimed with my personal experience as a computational linguist. For many years I had grown accustomed to the fact that working with real-life corpus data was seen in the computational linguistics research community as an eccentricity, but then in 1990 the atmosphere seemed to flip, quite abruptly. I remember a conference in Britain that year at which a series of computational linguists who to my knowledge had shown no interest in naturally-occurring data a few years earlier came forward to declare their belief in the value of corpora.
Putting these points together, I found myself wondering ‘Has empiricism won?’ Those of us who came of age as scholars of linguistics in the 1960s and 1970s were surrounded by people who urged that linguistics does not need empirical data, and that it gets on faster and more efficiently if it bypasses painstaking observation of natural usage and relies instead on speakers’ intuitive ‘knowledge’ of their language. I never believed that (Sampson 1975), and I found it surprising that one should need to make the case for the essential role of interpersonally-observable data, 400 years after Galileo. The Western world has known for centuries that a ‘science’ which allows people’s intuitions to be treated as authoritative will adopt false theories and will have no mechanism for replacing them by truth. But when I was a young lecturer, many linguists thought that the science of language was an exception.
For many years, a few of us were arguing that language is not a special case, and that those linguistic statements and theories which can in principle be treated as accountable to the evidence of observation ought to be, for just the same reasons as physics needs to be accountable to observation. But for a long time those of us who argued along these lines seemed to be a small minority making slow progress in face of an entrenched consensus. More recently, I had lost track of detailed developments within the linguistics profession, having shifted my own departmental affiliation to computer science in 1991; might it be that the discipline had finally passed a tipping-point of conversion to empirical methodological principles?
2. How empirical
should linguistics be?
Before discussing the literature survey that I carried out to assess
how far linguistics has converted to empirical methods, let me be clear about
how far I assume the subject should be empirical.
I wrote, above, about linguistic statements being accountable to
interpersonally-observable evidence whenever in principle they can be; but not
all aspects of linguistics can be empirical.
In the first place, in linguistics as in other sciences, analysis of methodological or mathematical underpinnings will not normally consist of testable statements about observations. But also, unlike physics, linguistics straddles the humanities/science borderline, and because of this borderline status there are valid areas of linguistics where empirical scientific method does not apply. Literary stylistics might be one example, and word semantics another (on the latter case, see Sampson (2001: chapter 11)).
On the other hand, in the study of syntax, in particular, it is perfectly possible to take a statement that sentence A is grammatical and sentence B is ungrammatical as a prediction that someone observing naturally-occurring language behaviour might hear an utterance of A but will not hear an utterance of B – so that an observation of B would call for the grammar to be reformulated (unless the observation can be explained away by some special factor, for instance a linguistics lecturer quoting an example of ungrammaticality). We know that people can alternatively interpret these statements as meaning something like ‘As a speaker I find that sentence A gives me a feeling of rightness, while B gives me a feeling of oddity or wrongness’; and many linguists have quite explicitly placed that kind of interpretation on statements about grammaticality, so that the statements cannot in principle be refuted by observation. Nothing I observe can show that you do not have the feeling you say you have. I am assuming that, in the large areas of linguistics for which rival interpretations like these are available, people who care about advancing human knowledge should choose the former interpretation, not the latter.
It is true that expressions of linguistic intuition are interpersonally-observable evidence, of a kind: they are data on what people say about their linguistic feelings. But there is no a priori reason to assume that such data must be a reliable guide to the properties of a speaker’s language, and there are plenty of grounds for saying that they are not. Wayne Cowart (1997) has shown that grammaticality judgements are open to empirical study, exhibit stability rather than unsystematic fluctuation, and so forth. Nevertheless, the phenomena studied by Cowart are judgements about language: not language itself. The two topics are certainly related, but the relationship is complicated and not well understood.
My aim in this paper is not to argue for the desirability of being empirical, but to assess how far linguistics has actually moved in that direction. Nevertheless, to make the discussion more concrete, the next section looks at two examples, one straightforward and one more complex, of how badly wrong linguistics can go if it does not subordinate itself to the authority of observation.
3. How intuition leads linguists astray.
I borrow my simple example from Laurie Bauer (1990: 25), who discusses a paper by Greg Carlson and Thomas Roeper (1980) the nub of which is stated on the first page as follows:
The heart of our analysis lies in this observation: addition of prefixes to verbs rules out non-nominal complements.
According to Carlson and Roeper this generalization was first stated by Ross, and then again by Roeper and Siegel (1978); Bauer says that it has often been repeated since. Yet, as Bauer also points out, it is just plain wrong. Bauer gives a series of examples that Carlsson and Roeper’s principle predicts to be impossible, but which in reality seem perfectly normal: two of them are Sam has a tendency to overindulge in chocolate, and Chris reaffirmed that everything possible was being done (with verbs containing the prefixes over- and re-, two of those listed by Carlson and Roeper). It seems questionable whether any linguist would continue to maintain the quoted generalization, if he considered Bauer’s potential counterexamples. In case any would, here are a few real-life counterexamples, found on the specified Websites by Google on 5 February 2004:
You will want to overindulge on this one, but …
www.tomarket-tomarket.com/thai_text.htm
Don’t overindulge in vitamin, mineral supplements.
www.freep.com/news/health/vit29_20030729.htm
Nah! – Overindulge in Coco Montoya!
www.epinions.com/content_7533399684
That’s a mere 65 days to trick or treat, overindulge on leftover Halloween candy …
www.charleston.net/stories/102703/loc_27gmlc.shtml
Russian President Vladimir Putin has reaffirmed that the Russian ruble will be …
english-pravda.ru/economics/2000/12/01/1231.html
… the Ohio Supreme Court has recently reaffirmed that Ohio’s current system of funding public education is …
www.worthington.k12.oh.us/pdf/phantrevres.pdf
… the Council reaffirmed that a just and peaceful solution to the problem of Germany can be reached …
www.nato.int/docu/comm/49-95/c651214a.htm
The two ministers also reaffirmed that “the establishment of a stable, permanent peace on the Korean Peninsula is the task of the Korean people” and agreed …
usinfo.state.gov/regional/ea/easec/roksec3.htm
If a statement as misguided as Carlson and Roeper’s can be repeated by linguist after linguist, it seems that they must be allowing the authority of earlier writers to outweigh evidence readily available from observation, in an almost mediaeval intellectual style.
Turning to the more complex example: Geoffrey Pullum has pointed out that many generative linguists, over many years, have asserted that a particular kind of question is vanishingly rare in English usage, and that this is crucial evidence in favour of the theory of innate linguistic knowledge. The fact that children learn how to form such questions correctly without ever hearing examples allegedly shows that principles of grammar must be built-in to us from birth. (After years as a Web publication, Pullum’s discussion of this reached conventional print as the ‘target article’ (Pullum and Scholz 2002) for a special issue of The Linguistic Review on ‘poverty of the stimulus’.)
The generative linguists quoted by Pullum and Scholz define the relevant structure as a yes/no question corresponding to a statement in which the main clause contains a subordinate clause preceding the main verb: for instance Since we’re here, can we get some coffee?, corresponding to the statement Since we’re here, we can get some coffee – the Since clause precedes the verb can. Linguist after linguist had claimed that these questions are vanishingly rare, without checking the data of real-life usage. Pullum found those claims grossly implausible, and showed that the structures defined were quite common in a corpus of written English.
I tried to strengthen Pullum’s case by searching a corpus more representative of the language young children hear (the demographically-sampled speech section of the British National Corpus, which at the time was for legal reasons not available to scholars such as Pullum working outside Europe). But the facts I found were subtler (Sampson 2002). Although generative linguists defined the class of allegedly-rare questions in the way I have defined it above, the specific examples they quoted were always drawn from a special case of that class, where the subordinate clause preceding the main verb is part of the subject – for instance Will those who are coming raise their hands? (corresponding to the statement Those who are coming will raise their hands, in which the relative clause who are coming modifies Those). It turned out that in spontaneous spoken English questions of this special kind are indeed systematically absent, although they are common in written English, and questions belonging to the wider class defined by generative linguists, but not to this narrower class, are common even in spontaneous speech.
In other words, on a grammaticality issue which lies at the heart of a leading attempt to make language shed light on human nature, the generative linguists shared one intuition – the relevant questions are all vanishingly rare – while Pullum and I shared a different intuition – all these questions are perfectly normal; and empirical evidence showed that we were all quite wrong.
In view of cases like these, it is not clear to me how anyone can suppose that intuition is a reliable source of data for linguistics (or any other science).
4. The Hirschberg
survey of computational linguistics.
To check how far the discipline has actually moved, I decided to carry
out a publication survey. Shortly
after embarking on this, I discovered that for my own special subfield of
computational linguistics or natural language processing (these alternative
phrases are used essentially for the same area of research by people whose
wider subject affiliation is to linguistics or to computing respectively) this
kind of survey had already been done, by Julia Hirschberg (1998). Her talk has
not been published, but salient points are repeated in various publications by
others, for instance Cardie and Mooney (1999). As stated by Cardie and Mooney,
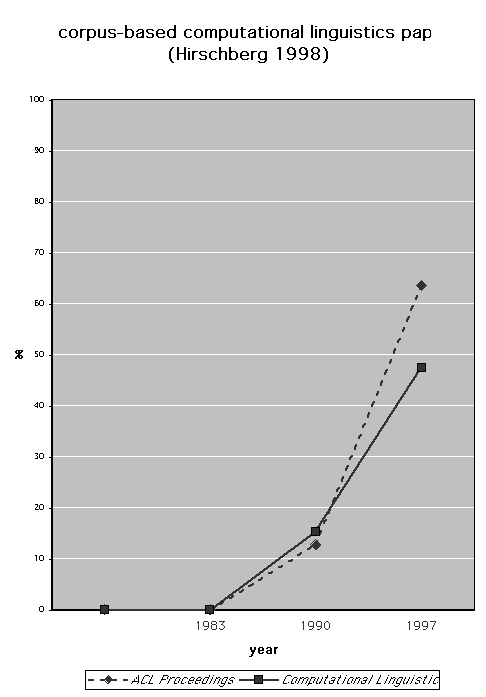
Hirschberg’s findings were striking (see figure 1):
a full 63.5% of the papers in the Proceedings of the Annual Meeting of the Association for Computational Linguistics and 47.4% of the papers in the journal Computational Linguistics concerned corpus-based research in 1997. For comparison, 1983 was the last year in which there were no such papers and the percentages in 1990 were still only 12.8% and 15.4%.
Figure 1 about here
The flat section at the left-hand side of figure 1 possibly misrepresents Hirschberg: the words ‘1983 was the last year’ seems to imply other zero years before 1983, but these may perhaps have been interspersed with years that did see a few corpus-based papers published. Nevertheless the broad picture is clear, and (even though very few of the selections in the Sampson and McCarthy anthology were drawn from the sources used by Hirschberg, as it happens) this picture matches my anecdotal impression very well: proportionately little or no corpus-based work up to 1990, and then a sudden explosion. Lillian Lee’s comment (Lee 2000: 177) on the same findings is ‘Nowadays, the revolution has become the establishment’.
But that is natural language processing, which could well be a special case. Many researchers contributing to ACL meetings or to Computational Linguistics work in computer science rather than linguistics departments, and these have a very different ‘culture’ of methodological assumptions. For one thing, computer scientists even if they work on natural language processing are not much influenced by linguistic discussion of ‘competence versus performance’. If researchers come to natural language from a computing rather than linguistic background, they may never have encountered these concepts. Even if they are aware of them, the ethos of computer science encourages a focus on practical systems that have or lead to potential applications in real-life circumstances, rather than on abstract theoretical study of human psychological mechanisms. Much research on natural language processing is best classified as engineering. I wanted to look at how things have moved in general linguistics as a pure science.
5. My literature
sample.
I therefore carried out a literature survey comparable to Julia
Hirschberg’s, but with a longer time depth, on the journal Language, which is generally recognized as the
world’s leading linguistics journal (see e.g. Zwaan and Nederhof 1990: 554),
and which has long aimed to publish the best in the field as a whole,
irrespective of particular theoretical orientations (cf. Joseph 2002: 615–16).
Although Language
belongs to an American learned society, its authors include plenty of
non-American scholars. (An initial
plan to get fuller international coverage by additionally using the British Journal
of Linguistics had to be
given up, because this journal was founded much more recently than Language and had very small numbers of papers in
early volumes, which would have made statistics difficult to interpret.)
I examined the 1950 volume of Language, to establish a baseline well before the emergence of the concepts of linguistic competence and of native-speaker intuition as a possible basis for linguistic research, and then sampled a proportion of volumes from 1960 up to 2002. For statistical purposes I considered only articles in the normal sense, excluding reviews and review articles, ‘Editor’s Department’ pieces, and items such as reader’s letters, ‘notes’, and ‘miscellanea’, which have been included in Language at different periods.
I sampled volumes at a rate of two out of five up to 1990 (years ending in 0, 2, 5, and 7) and two out of three after that date (1991 and every third year thereafter omitted). There were two reasons for sampling more densely after 1990: the period since that date is short but specially interesting because of the apparent discontinuity discussed above, but also, the number of papers per volume of Language has decreased quite strikingly over the period (the 1967 volume contained 44 papers, apart from reviews, etc., while in the 1990s the annual figures were only about 15).
6. Evidence-based,
intuition-based, or neutral.
I assigned papers in the sampled volumes to three categories: evidence-based, intuition-based, and
‘not applicable’ or neutral.
Papers were assigned to the neutral category for several different reasons. The question I am interested in is how far linguists have felt it appropriate to cite the authority of interpersonally-observable data rather than relying on introspection in order to support claims that might be challenged by other scholars. We have seen that some valid topics in linguistics do not purport to be empirically testable, for instance a discussion of methodology is likely to consist essentially of recommendations about how linguists ought to proceed, which cannot be ‘confirmed’ or ‘falsified’ by any particular factual observations. That then would be one kind of paper classified as neutral; but that was not the commonest case. A different kind of case would be a paper on a topic in the history of linguistics, which is certainly empirical in the sense that linguist A either did or did not advance particular views in a book published at a particular date, and if anyone disputes it one can go to the library to check: but nobody suggests that native-speaker intuitions cover facts like that, so again I assigned papers on history of linguistics to the neutral category.
Apart from cases like these, though, there are also large areas of linguistic data which are in principle entirely testable, and which do relate to the kinds of issue that speakers may have introspective beliefs about, but for which one would not expect the most empirically-minded linguist to cite observational evidence, because one would not expect others to challenge those data. Suppose for instance that the data for a research paper include the genders of a range of common French nouns. It would be possible for the article to include citations of real-life utterances in which the relevant nouns are used in their respective genders, but no author would trouble to do this, because if anyone thinks the genders may be wrong it is so easy to look the words up in a dictionary.
The principle here was classically stated by Karl Popper (1968: 111):
Science does not rest upon solid bedrock. … It is like a building erected on piles. The piles are driven down from above into the swamp, but not down to any natural or ‘given’ base … We simply stop when we are satisfied that the piles are firm enough to carry the structure, at least for the time being.
Empirical scientific discourse cannot quote ultimate observable authority for every datum it uses, because any premiss no matter how seemingly well-established could in principle be challenged; a scientist takes a view on which of his premisses need explicit empirical support and which can safely be taken for granted. Genders of common French nouns surely fall into the latter group, even for linguists who see the subject as accountable to observation rather than intuition; whereas, for those linguists, the grammatical acceptability of some long and unusual sequence of words is likely to fall into the former group (of data that do need support).
This meant that in doing my literature survey I had to take a view on which papers used premisses for which an empirical linguist would expect evidence to be cited, and which ones used only premisses that empirical linguists were likely to concede without cited evidence: the latter type of paper went into the neutral category, and accounted for the largest part of its contents.
I developed various rules of thumb for making these decisions consistently. For instance, papers dealing with finite linguistic subsystems, particularly phonology or morphology, were normally counted as neutral, and so were articles about Greenbergian word-order universals – word-order is an aspect of syntax, which as a whole is a non-finite system, but choices between SVO, SOV, and VSO, or between noun + adjective and adjective + noun, are finite subsystems within syntax. Conversely, papers containing examples marked with asterisks or question marks to denote ungrammaticality or doubtful grammaticality were normally treated as cases to which the evidence-based versus intuition-based distinction was applicable. These rules of thumb were overridable in either direction – a paper which used ungrammaticality asterisks solely to mark things such as gender errors (*le voiture) would be ‘neutral’, while a paper on the phonology of some little-known language or dialect which did find it appropriate to cite evidence of naturally occurring utterances observed at particular times and places would be ‘evidence-based’. My rules for deciding whether the evidence-based versus intuition-based distinction was or was not applicable to a paper became more elaborate than there is space to go into here, but I must ask the reader to believe that these decisions were made in about as consistent a fashion as was reasonably possible.
7. How much evidence
counts as ‘evidence-based’?
For a paper where it seemed that the distinction was applicable, there
was a further issue about deciding consistently whether or not the paper should
count as evidence-based. We have
seen that an empirical scientist is not expected to quote observational evidence
for every one of his premisses, only for the ones he sees as open to challenge.
Here, my rule of thumb was that a paper which quoted observational support for at least two separate data items counted as evidence-based. The paper might also make numerous other (un)grammaticality claims without quoting evidence, but that could be a reasonable empirical strategy if the author saw those claims as less likely to be challenged. A single citation of evidence in a paper otherwised based on introspection was discounted, as when Maria-Luisa Rivero’s ‘Referential properties of Spanish noun phrases’, which includes numerous unsupported claims about (un)grammaticality and semantic anomaly of example sentences which are often long enough to spill over two lines, quotes one example from Cervantes in a footnote (Rivero 1975: 36 n. 7). There are many reasons why a linguist who sees intuition as authoritative might nevertheless choose to include a single authentic example in his paper, for instance as a rhetorical strategy to capture the reader’s interest. If an author cites real-life evidence twice or more, I took this as a significant indication of a propensity to treat observation as the ultimate authority.
The threshold of two is arbitrary. Sometimes it forced me to count as evidence-based some paper which, overall, seemed to belong much better in the intuition-based category. Geoffrey Pullum and Deirdre Wilson’s 48-page ‘Autonomous syntax and the analysis of auxiliaries’ (1977) makes numerous unsupported and sometimes, to my mind, quite debatable grammaticality claims (for instance it is not obvious to me that I had my servant bring in my bags cannot be reduced to I’d my servant bring in my bags, or that there is a difference in grammaticality between Sam was being examined by a psychiatrist, and Bill was too, and Sam was being examined by a psychiatrist, and Bill was being too); but then their last two examples, numbered (70) and (71), are respectively a sentence taken by Madeline Ehrman (1966: 71) from the Brown Corpus, and another sentence given them by Andrew Radford who heard it on a BBC current-affairs programme. So Pullum and Wilson (1977) had to go into the evidence-based category. Rather than using an absolute threshold figure, it might ideally have been preferable to set the threshold at some proportion of all data items quoted, but that would have required a great deal of complicated counting which would have been very hard to carry out in a consistent manner, even if I had had enough time. The division between evidence-based and intuition-based papers clearly had to rely on something solider than my subjective impressions; probably any objective criterion I could have chosen would have yielded odd decisions in some individual cases.
Notice on the other hand that where observable evidence was cited, I made no distinction between cases where this was drawn from a standard corpus such as Brown or the British National Corpus, and cases where authors quoted other sources, such as overheard conversations or literary works, or for instance instrumental readings in the case of research on phonetic topics. Intersubjectively observable evidence is evidence, wherever it is found. Corpus linguists compile and work with standard corpora because they are specially convenient data sources, but there is no reason to suggest that evidence has to occur in a recognized corpus to count as evidence. In the earlier part of the period examined, authors commonly quoted literary examples and rarely or never quoted from electronic corpora, because they were familiar with the former and had no access to the latter. Until quite recently, very few people had access to representative, documented recordings of spontaneous spoken language, so it would be unreasonable to reject an observation of an overheard remark just because it is difficult for a sceptical reader to cross-check it. Such a datum was potentially intersubjectively observable; the difficulty of checking in practice just means that spontaneous spoken language has been a difficult topic for empirical research until recently – which is true.
8. Explicit
authenticity claims.
A special classification problem arose with the very many cases, for
instance in papers on exotic languages, where an author cited examples from
earlier publications without saying whether the source publications quoted the
examples from observed usage or made them up. Sometimes it is easy to guess from the nature of the
examples that some were authentic and others invented. Thus, Evans, Brown, and Corbett (2002:
126) quote a passage in the Australian language Kunwinjku whose translation
begins ‘The red color in the crocodile is the blood from Likanaya’. Not only do they not explicitly assert
that this was a real-life utterance but they do not even (so far as I can see)
explain the abbreviation they give for their source; however I surmise that the
example is a genuine extract from something like a native folktale, because it
does not sound constructed.
Conversely, when David Basilico (1996: 509) quotes from Molly Diesling a
German subordinate clause daß Otto Bücher über Wombats immer liest, ‘that Otto always reads books about
wombats’, I feel convinced that Diesling made it up. Often, though, quoted examples could have been either
authentic or invented, and chasing up all the cited publications would have
taken far more time than I had available.
However, this is less of a problem than it seems, if we consider that the issue we are fundamentally concerned with is whether authors treat observation rather than introspection as the source of scientific authority. An author who assumes that observation is what matters and who quotes authentic data from an earlier publication will surely not fail to make clear that it is indeed cited as authentic, in an intellectual environment where many other linguists are using invented examples. If an author cites such data without making an explicit authenticity claim, that seems to imply that he does not see the fact of their being real-life data as specially significant. For instance, Donald Winford’s paper on Caribbean English Creole syntax (Winford 1985) quotes many examples from previous researchers which to me seem to have the ring of authenticity, for instance ah me fi aks dem if dem neva gi im no nurishment (translated as ‘I was supposed to ask them if they ever gave him any nourishment’), or mi no iebl unu tieraof mi kluoz (‘I can’t risk the chance of you tearing off my clothes’); but Winford never actually asserts that these are taken from real-life usage, and he says that many other examples ‘are based on my own intuitions as a native speaker of Trinidadian Creole’, which makes it clear that observed occurrence in natural usage is not a crucial issue for Winford.
So there was no reason for me to chase up earlier publications when classifying a paper as based on evidence or intuition. What mattered was whether the paper I was classifying itself made an authenticity claim, not whether the data were or were not in fact authentic.
Needless to say, there were plenty of marginal cases where it was hard to decide whether an authenticity claim was explicit, but again I developed rules of thumb to make such decisions consistent rather than subjective. For instance, where linguists quoted American Indian examples from transcriptions of naturally-occurring speech, it seemed that they commonly used the term ‘texts’ to describe these records, whereas field notes of examples elicited from informants were not called texts; so I treated the term ‘text’ in such cases as an explicit authenticity claim. (Examples produced by asking an informant ‘Can you say so-and-so in your language?’, inviting a grammaticality judgement on an invented example, or ‘How do you say such-and-such in your language?’, inviting a translation, are no less intuition-based than data constructed by the linguist for his own language: they merely treat the informant’s intuition rather than the linguist’s as the source of authority.)
9. Raw and smoothed
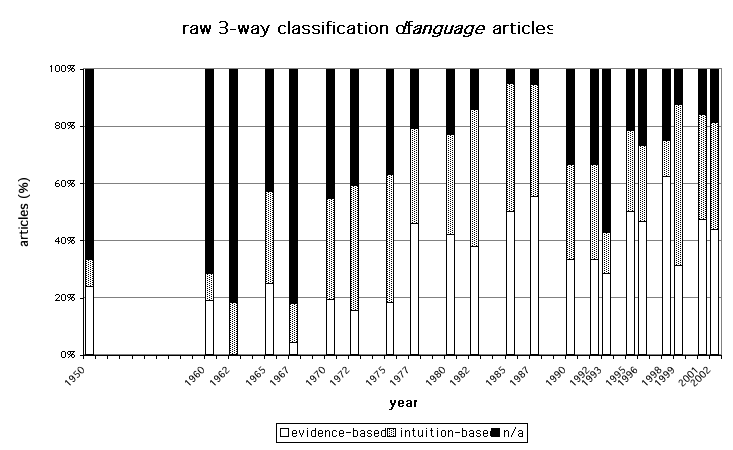
counts.
Figure 2 shows the year by year results of imposing this three-way
classification on Language papers from the sample years.
Each bar represents 100% of that year’s papers, within which the white
section stands for evidence-based cases, the dotted section represents entirely
intuition-based cases, and the black section represents neutral cases. Because I tried to define ‘not
applicable’ in such a way that it would include papers based on empirical
premisses which are too well-established to be worth challenging, it follows
that the dotted sections of the bars should include papers quoting unsupported
premisses that many linguists might see as questionable – and they certainly
do. To me it was quite surprising
to find Geoffrey Huck and Younghee Na (1990) claiming without evidence that To
whom did Mary give a pie during yesterday’s recess of BILLY’S is good English but that What did Tom
speak to Ann yesterday about? is bad English, or to encounter unsupported claims by Samuel Bayer
(1996) that one cannot say I made John above suspicion but it is all right to say That
Himmler appointed Heydrich and the implications thereof frightened many
observers. However, querying other linguists’
intuitions is easy sport, and I shall not indulge it further.
Figure
2 about here
The raw quantities displayed in figure 2 are not particularly easy to interpret. Perhaps the most noticeable feature is the way that the neutral category accounts for a specially large proportion of the early samples. A principal reason for that is the well-known fact that research on the finite areas of phonology and morphology was in vogue in the 1950s and early 1960s, whereas syntactic research came to the fore in the later 1960s and beyond.
Although I have explained that topics relating to finite systems were normally classified as neutral, a preponderance of these topics in the earlier years surveyed does have relevance for the question how far linguists were empirically minded. Gathering observational data on non-finite systems like syntax was relatively difficult before computers and computer corpora became routinely available to linguists, which did not really happen until the 1980s. If a linguist is empirically-minded and cannot easily get hold of syntactic data, he will naturally be drawn to work on areas like phonology where data availability is not usually a difficulty. So the large amount of black towards the left-hand side of figure 2 is one indirect indication that linguistics at that period tended to make empirical assumptions, and the fact that the black is greatly reduced long before the 1980s correlates with the fact that linguists came to believe that unavailability of observational data was no barrier to syntactic resarch.
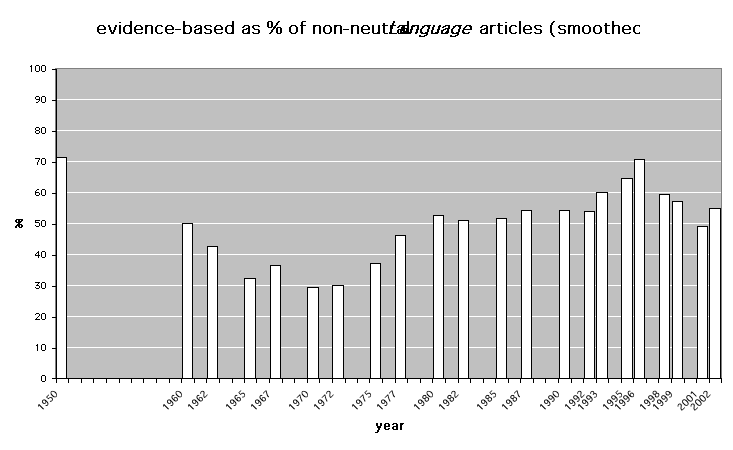
The central facts, though, are represented more clearly in figure 3, which is based on the same numerical counts as figure 2 but reworks the display in two ways. In the first place, figure 3 excludes the neutral papers: for each sample year the bar represents the number of evidence-based papers as a percentage of the total of evidence-based and intuition-based papers. Secondly, except for the 1950 figure which is separated from the others by a large gap in time, the individual year figures are smoothed by averaging with neighbouring figures, which is an accepted statistical technique for revealing underlying trends in an irregular series. The observation-based and intuition-based counts for each sample year were averaged with the next earlier and later sample counts (and the counts for the first and last years of the series were smoothed by half-weighting the counts for the sole adjacent years when averaging), before percentages were calculated from the smoothed counts.1
Figure
3 about here
10. The match
between statistics and history.
The main features of figure 3 square well with my impressions of the
development of linguistics over half a century. In the first place, the 1950 figure, before the emergence of
generative linguistics, shows a high proportion of observation-based papers. This was the period when Charles Fries
was working on The Structure of English (Fries 1952) – surely entitled to be seen as the
first major milestone in corpus-based linguistic science.
In fact the 1950 figure deserves detailed analysis, because it was a problematic year to assess and I could have chosen an even higher observation-based figure without distorting the facts. One item that I counted as intuition-based, William E. Welmers’s ‘Notes on two languages in the Senufo group’, was published in two parts in separate journal issues – if I had treated them as two distinct papers, the bar for 1950 in figure 3 would be lowered from 71% to 63%, but it seemed that inclusion of the two parts was a single editorial decision and the separate parts applied identical methodologies to two related languages, so it would be statistically misleading to count them twice. However, Welmers’s descriptions were mainly concerned with phonological and morphological levels of the languages described; I counted the material as intuition-based only because it included some quite brief and limited discussion of syntax which appeared to rely on elicitation from informants. And the other item I counted as intuition-based, Charles Hockett’s famous paper ‘Peiping morphophonemics’, had an even better claim to be classified as neutral: as its title suggests, it is not about syntax at all, but it happens to begin by quoting some specimen Chinese sentences that have every appearance of authenticity but for which Hockett made no explicit authenticity claim, which would have been fairly irrelevant to his purpose. I wanted to play absolutely fair, so I put this paper into the intuition-based category. On the other hand, the papers I have counted as observation-based, for instance Henry and Renée Kahane’s ‘The position of the actor expression in colloquial Mexican Spanish’, and Simon Belasco’s ‘Variations in color and length of French [a]: a spectrographic study’, are very clearly observation-based: they deal centrally with non-finite systems and refer to abundant authentic data of various categories. It would not be hard to argue that the 1950 bar in figure 3 ought to be raised from 71% to 100%.
By the early 1960s, figure 3 shows a falling trend; this was the time of the famous conversation in which R.B. Lees told Nelson Francis that compiling the Brown Corpus was ‘a complete waste of … time’ because as a native speaker ‘in ten minutes you can produce more illustrations of any point in English grammar than you will find in many millions of words of random text’ (quoted by Biber and Finegan 1991: 204). The lowest proportions of evidence-based papers occur in the years round 1970, which I remember as the high-water period of linguistic rejection of empiricism. After the early 1970s, the slope rises again.2
Skimming through these old volumes of Language I encountered sporadic comments which showed the authors as having been well aware of these changing trends at the time. For instance, Charles Hockett in his LSA Presidential address (Hockett 1965) includes spirited comments on the ‘group of Young Turks, armed with a vitally important idea and with enormous arrogance, [who were] winning converts and making enemies as much through charisma as by reasonable persuasion’ – later in the paper Hockett names names; while by 1975 Matthew Chen and Bill Wang argue that ‘it is perhaps time for a return to an enlightened empiricism’, and David S. Rood (1975: 336) comments:
No serious linguist questions the importance of theory or of the search for true universals … But certainly one of the reasons for, and one of the results of, a return to data-oriented sessions at the LSA … is a recognition by most linguists that neither of these activities is valid or useful apart from consideration of what real languages do.
11. A long way left
to go.
On the other hand, another feature of figure 3 which I find striking is
how gentle the upward rise is.
Compare this slope with the cliff rearing up after 1990 in figure 1,
based on Julia Hirschberg’s survey of corpus linguistics. (The difference is not caused by
different graphic scales. Figure 1
is in portrait and figure 3 in landscape format because the latter covers a
longer period of years than the former, but I was careful to make the aspect
ratios between the two axes identical:
the difference between the angles of slope is real.)
True, linguists might observe that the computing world is notorious for chasing after whatever fashion happens to be flavour of the month, be it sensible or foolish; they might pride themselves that the more gradual shift of figure 3 is a sign of greater maturity in linguistics. Others might hold, though, that maturity lies in fully embracing the long-established disciplines of empirical science.
Since it is computer corpora which have made it easy for syntactic research to move on from intuitive to evidence-based techniques, it is natural that computational linguistics has run ahead of general linguistics in shifting away from the anti-empiricism of the 1960s towards more scientifically respectable methods. And even if linguists had become thoroughly empirically minded, doubtless the bars of figure 3 would still not consistently reach quite up to the 100% mark. The complexities of classifying papers in these terms are so great that I am sure even in that situation a proportion of worthwhile papers would still fall into the ‘intuition-based’ category. But the bars would surely get much closer to 100% than they show signs of doing to date. Indeed, figure 3 shows a slight downturn since the mid-1990s: it seems that opponents of empirical methods may be mounting a somewhat successful rearguard action.
Anecdotal evidence supporting this would include recent remarks by Thomas Nunnally, reviewing Rosamund Moon’s corpus-based investigation of English fixed expressions:
it is intuition that signals ill-formedness, not frequency of formations per million words … [Moon’s] shortchanging of native speaker understanding as evidence until a massive corpus can locate, say, five examples is worrying (Nunnally 2002: 177)
This review was the first occasion I am aware of when the corpus-based approach has been explicitly attacked as positively undesirable, rather than just bypassed by generative linguists as uninteresting. But it was not the last: in 2003 Frederick Newmeyer used his LSA Presidential Address to argue against ‘usage-based’ linguistics, urging that ‘There is no way that one can draw conclusions about the grammar of an individual from usage facts about communities’ (Newmeyer 2003: 696). It will be interesting to see whether views such as Nunnally’s and Newmeyer’s presage a strengthening of the downward trend which seems to be visible at the right-hand side of figure 3.
Although there have been changes over thirty years, the virtues of empirical scientific method evidently remain less thoroughly accepted in linguistics than in other scientific disciplines.
References
Basilico, D. (1996). Head position and internally headed relative clauses. Language, 72, 498–532.
Bauer, L. (1990). Be-heading the word. Journal of Linguistics, 26, 1–31.
Bayer, S. (1996). The coordination of unlike categories. Language, 72, 579–616.
Belasco, S. (1950). Variations in color and length of French [a]: a spectrographic study. Language, 26, 481–8.
Biber, D, and E. Finegan. (1991). On the exploitation of computerized corpora in variation studies. In Karin Aijmer and B. Altenberg, eds., English Corpus Linguistics. London: Longman.
Cardie, Claire, and R. J. Mooney. (1999). Guest editors’ introduction to the special issue on Machine Learning and Natural Language. Machine Learning vol. 1, no. 5.
Carlson, G., and T. Roeper. (1980). Morphology and subcategorization: case and the unmarked complex verb. In T. Hoekstra, H. van der Hulst, and M. Moortgat, eds., Lexical Grammar (pp. 123–64). Dordrecht: Foris.
Chen, M. Y., and W. S.-Y. Wang. (1975). Sound change: actuation and implementation. Language, 51, 255–81.
Cowart, W. (1997). Experimental Syntax: applying objective methods to sentence judgments. Thousand Oaks, Calif.: SAGE Publications.
Ehrman, Madeline E. (1966). The Meanings of the Modals in Present-Day American English. The Hague: Mouton.
Evans, N., D. Brown, and G. Corbett. (2002). The semantics of gender in Mayali. Language, 78, 111–55.
Fries, C. C. (1952). The Structure of English: an introduction to the construction of English sentences. New York: Harcourt Brace.
Hirschberg, Julia. (1998). ‘Every time I fire a linguist, my performance goes up’, and other myths of the statistical natural language processing revolution. Invited talk, 15th National Conference on Artificial Intelligence (AAAI-98).
Hockett, C. F. (1950). Peiping morphophonemics. Language, 26, 63–85.
Hockett, C. F. (1965). Sound change. Language, 41, 185–204.
Huck, G., and Younghee Na. (1990). Extraposition and focus. Language, 66, 51–77.
Joseph, B. D. (2002). The Editor’s department. Language, 78, 615–18.
Kahane, H. and Renée. (1950). The position of the actor expression in colloquial Mexican Spanish. Language, 26, 236–63.
Lee, Lillian. (2000). Review of Manning and Schütze, Foundations of Statistical Natural Language Processing. Computational Linguistics, 26, 277–9.
Newmeyer, F. J. (2003). Grammar is grammar and usage is usage. Language, 79, 682–707.
Nunnally, T.E. (2002). Review of Moon, Fixed Expressions and Idioms in English. Language, 78, 172–7.
Popper, K.R. (1968). The Logic of Scientific Discovery (revised English translation of 1934 German original). London: Hutchinson.
Pullum, G. K., and Barbara C. Scholz. (2002). Empirical assessment of stimulus poverty arguments. In Ritter (2002), pp. 9–50.
Pullum, G. K., and Deirdre Wilson. (1977). Autonomous syntax and the analysis of auxiliaries. Language, 53, 741–88.
Ritter, Nancy A., ed. (2002). A Review of the Poverty of Stimulus Argument. A special issue of The Linguistic Review, vol. 19, nos. 1–2.
Rivero, Maria-Luisa. (1975). Referential properties of Spanish noun phrases. Language, 51, 32–48.
Roeper, T., and M. Siegel. (1978). A lexical transformation for verbal compounds. Linguistic Inquiry, 9, 199–260.
Rohlf, F.J., and R.R. Sokal. (1981). Statistical Tables (2nd edn). San Francisco: W.H. Freeman.
Rood, D. S. (1975). The implications of Wichita phonology. Language, 51, 315–37.
Sampson, G. R. (1975). The evidence for linguistic theories. Chapter 4 of Sampson, The Form of Language, London: Weidenfeld and Nicolson; a version reprinted in Sampson (2001), chapter 8.
Sampson, G. R. (2001). Empirical Linguistics. London and New York: Continuum.
Sampson, G. R. (2002). Exploring the richness of the stimulus. In Ritter (2002), pp. 73–104.
Sampson, G.R., and Diana F. McCarthy, eds. (2004). Corpus Linguistics: readings in a widening discipline . London and New York: Continuum.
Siegel, S., and N.J. Castellan. (1988). Nonparametric Statistics for the Behavioral Sciences (2nd edn). New York: McGraw-Hill.
Welmers, W. E. (1950). Notes on two languages in the Senufo group. Language, 26, 126–46 and 494–531.
Winford, D. (1985). The syntax of fi complements in Caribbean English Creole. Language, 61, 588–624.
Zwaan, R. A., and A. J. Nederhof. (1990). Some aspects of scholarly communication in linguistics: an empirical study. Language, 66, 553–7.
Notes
* I am grateful to my colleage John Carroll and to participants at the Corpus Linguistics 2003 conference, Lancaster, March 2003, for useful comments; responsibility for the conclusions is mine alone. The research was supported in part by the Economic and Social Research Council, UK, under grant reference R00023 8146.
1Because smoothing was done before calculating observation-based percentages, years with fewer papers overall contributed less to the smoothed figures: this was important in view of the large year-to-year fluctuations in numbers of papers published.
2To check that the trends which appear in figure 3 are real rather than chance fluctuations, I applied the runs test described e.g. in Siegel and Castellan (1988: 58–64) to a sequence showing, for each of the 22 sample years, whether the ratio of unsmoothed counts of evidence-based to intuition-based papers in that year was greater or less than the mean of the 22 ratios. I used the runs test as a one-tailed test, since we are interested only in whether runs are specially few, not whether they are specially numerous. The observed figure of seven runs is significant at the .05 level according to the criterion given by Rohlf and Sokal (1981: table 28): the variation is unlikely to be random.
![]()